

今回の記事では下記のような悩みを解決します。
「ランダムフォレストというワードをよく目にするので、ランダムフォレストについて知りたい」
「ランダムフォレストのpythonでの実装方法が知りたい」
早速解説していきます。
ランダムフォレストとは

ランダムフォレストは異なる決定木を複数作成し、個々の決定木の予測結果を統合して、最終的な予測を出力する手法です。
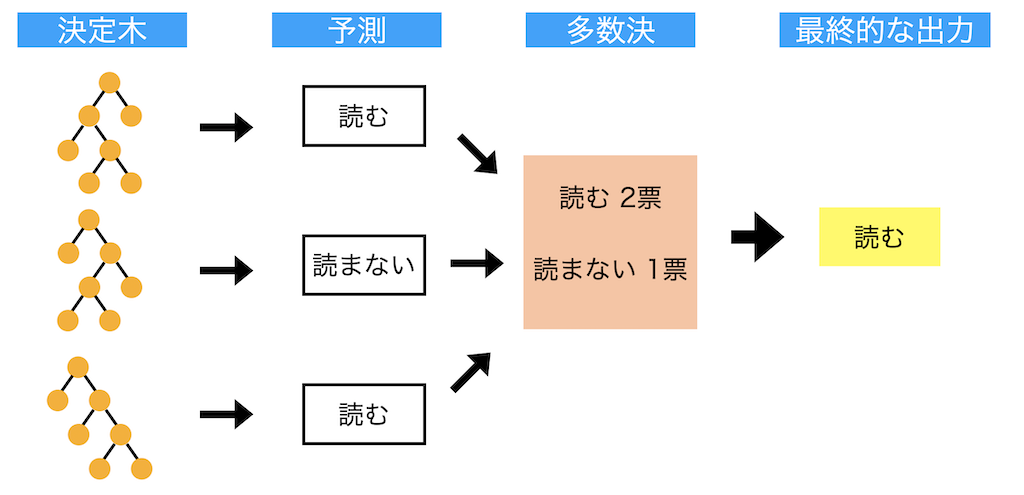
ランダムフォレストのイメージ図を下記に示します。
今回は、「私のブログを読む or 読まない」をランダムフォレストで予測する場合を考えます。
個々の決定木で読む or 読まないを予測し、多数決を持って最終的な予測結果を出力をする(今回であれば読むと予測される)という流れになります。
ランダムフォレストの数学は難しいですが、「決定木を複数作って予測して、多数決を取って最終的な予測結果を出力してるんだ〜」くらいの理解度でOKです。
ランダムフォレストは、回帰・分類両方に対応しており、回帰では個々の決定木の平均値、分類では多数決で最終的な予測結果を出力します。
決定木については下記記事参照。

次に決定木との違いについて解説します。
決定木との違い
決定木との違いを下記に示します。
・個々の決定木を可視化できない
決定木は、ツリーが深くなると木構造が複雑になり過学習が起きやすいという問題がありますが、 ランダムフォレストは決定木よりも過学習しにくく、汎化性能(未知のデータに対して正解する能力)に優れています。
一方で、決定木モデルは決定木を可視化できるのに対し、ランダムフォレストは個々の決定木を可視化できないので、モデルの可読性は決定木に劣ります。
そのため、目的に応じて使い分ける必要があります。
ランダフォレストのイメージは掴めたと思うので、次にpythonでの実装について解説していきます。
ランダムフォレストの実装

ランダムフォレストを使用することで、下記のことができます。
・変数重要度の算出
上記2点について、タイタニック予測問題を使用して解説します。
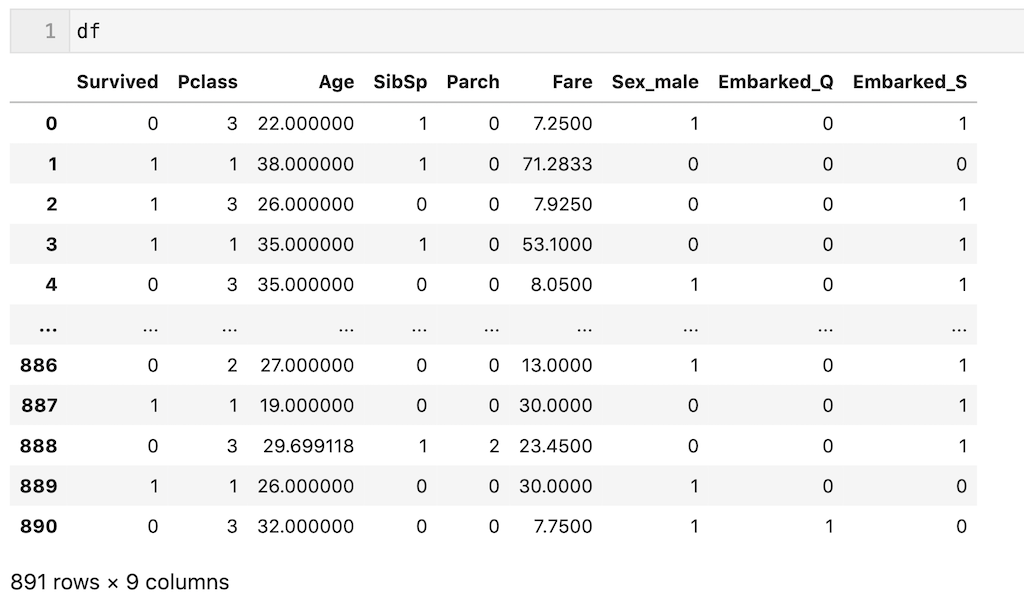
今回は解説を簡単にするために、前処理後のデータ(df)を使用します。一応前処理を簡単に説明すると、’Plass’、’Age’、’SibSp’、’Parch’、’Fare’、’Sex’、’Embarked’の7個の説明変数を使用し、欠損値を平均値、最頻値で補完し、カテゴリカル変数をダミー変数化しています。今回は前処理が目的ではないので、わからなくても全く問題ないです。
dfを下記に示します。
解説のため、dfの700行目までを訓練データ(df_train)、700行目以降をテストデータ(df_test)とします。
df_train = df.iloc[:700, :] df_test = df.iloc[700:, :]
また’Survived’列以外を説明変数(X)、’Survived’列を目的変数(y)とします。それぞれ訓練(train)、テスト(test)としています。
X_train = df_train.drop(columns = ['Survived']) y_train = df_train['Survived'] X_test = df_test.drop(columns = ['Survived']) y_test = df_test['Survived']
データの説明は以上です。
ランダムフォレストの実装方法を早速解説していきます。
ランダムフォレストの学習と予測
モデルの学習は下記のコードで実装できる。タイタニック予測問題は分類なのでRandomForestClassifierを使用。回帰の場合はRandomForestRegressorを使用すればいい。
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier( ) model.fit(X_train, y_train)
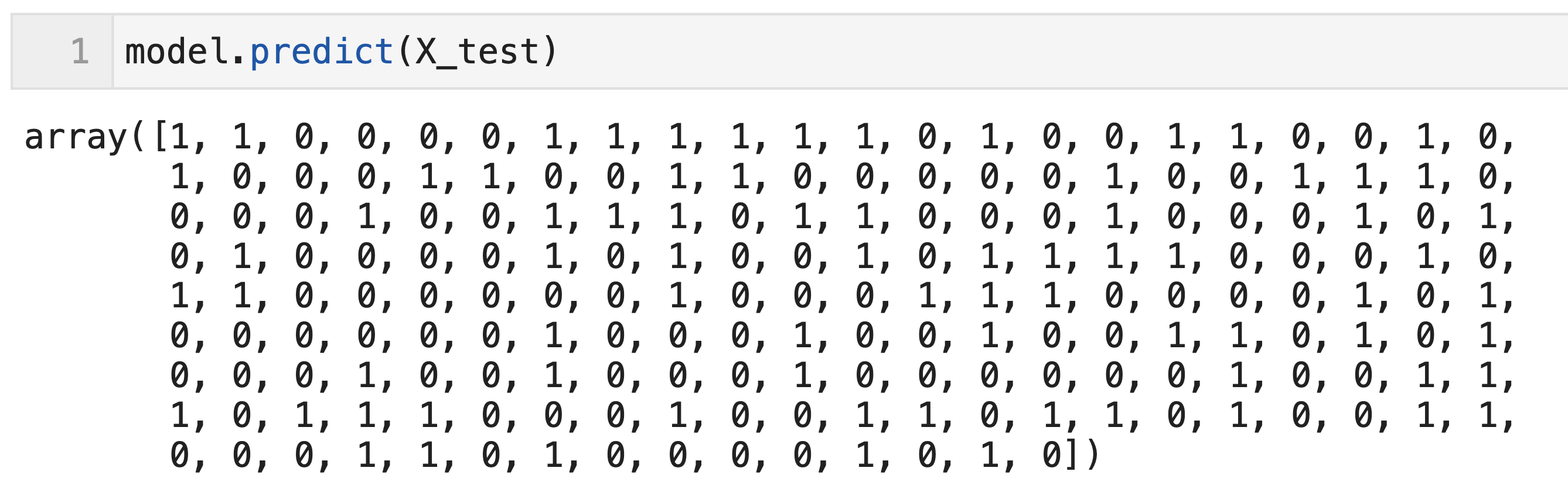
上で学習したモデルを用いて予測する場合は下記のコードで実装できる。df_testの191個のデータに対する予測(0 or 1が出力されている)を実行できていることが確認できる。
model.predict(X_test)
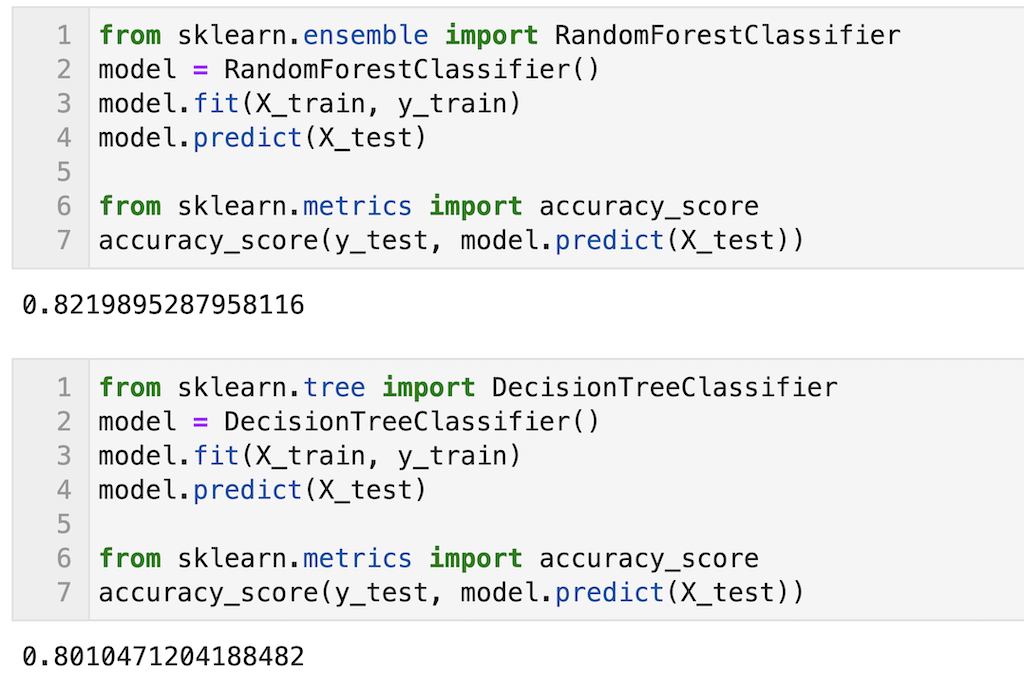
参考程度に同じデータを使って決定木と予測精度の比較を示します。
正解率を算出していますが、少しランダムフォレストの方が精度が高いことが確認できます。タイタニック予測問題ではこの程度の差ですが、データ数が多くなったりすると精度にもう少し差がでます。
ランダムフォレストのモデル構築の注意点
同じデータを使ったとしても、ランダムフォレストでは学習の際に、毎回同じ決定木が生成されないため、厳密には学習の度に都度別のモデルが生成されます。予測精度に大きな差は出ないですが、学習の度に予測精度が変わることに注意してください。
調整すべきハイパーパラメータ
一般的によく調整されるハイパーパラメータを下記に示す。
・決定木の深さ(max_depth)
0.01%でも予測精度を高めたい場合は他のハイパーパラメータも調整すべきですが、大体この辺りのハイパーパラメータを調整できれば問題ないと思います。
またデフォルト(ハイパーパラメータの調整なし)でもある程度の精度は出るので、まずはデフォルトで予測精度を確認してみて、精度が足りなければハイパーパラメータを調整するというやり方でOKです。
書き方の参考のために、コードを下記に示します。
例なのでn_estimators = 100、 max_depth = 10としてます。
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators = 100, max_depth = 10) model.fit(X_train, y_train)
次は重要度の算出について解説します。
重要度の算出
重要度の算出はfeature_importances_で算出できます。今回はランダムフォレストのモデルをmodelと定義しているため、model.feature_importances_と記載すればOK。
model.feature_importances_

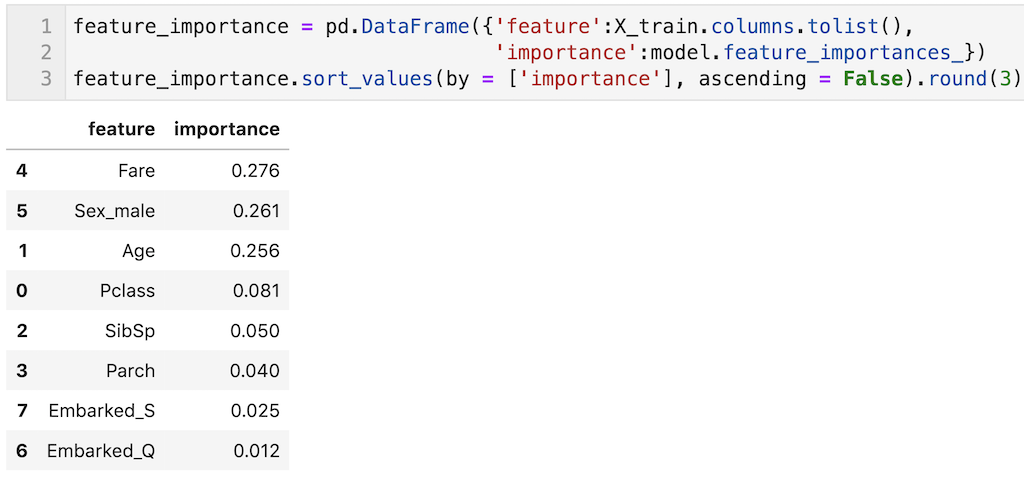
これだとわかりにくいので、説明変数と重要度を表形式(pandas dataframe)で出力して、変数重要度の大きい順に表記しました。
今回のモデルではFareやSex_male、Ageが比較的重要度が大きい結果となっていることが確認できます。
feature_importance = pd.DataFrame({'feature':X_train.columns.tolist(),
'importance':model.feature_importances_})
feature_importance.sort_values(by = ['importance'], ascending = False)
変数重要度の注意点
最後に少しだけ注意点を書きます。
変数重要度では説明変数が正・負、どちらに効果があるのかわからない
重回帰分析では偏回帰係数の符号から、その説明変数が正に働いているのか、負に働いているのか、わかるが、変数重要度では正・負、どちらに効果があるのかわかりません。あくまで「どの説明変数が寄与しているのか」くらいしかわかりません。
精度の良いモデルを作らないと変数重要度の議論ができない
変数重要度の大きさは、「モデル構築時にどれだけその説明変数が寄与しているのかという寄与度」であるため、精度の高いモデルを構築できなければ、変数重要度は意味をなさない。精度の高いモデルであるから変数重要度(どの説明変数が重要なのか)が議論できるようになる。そのため、変数重要度を議論する際は、モデルの精度を確認してからにしましょう。
同じデータを学習しても毎回同じ重要度にはならない
個々の決定木が厳密にいうと同じではないため、学習の度に重要度の結果は変わります。
ランダムフォレストは非常に強力な機械学習手法でkaggleなどのコンペでも頻繁に使われています。ですので今回の記事で是非ランダムフォレストについて理解を深めてください。
今回の記事はここまでです。最後まで読んでいただきありがとうございます。
皆さんの機械学習の勉強がさらに進み、理解が深まることを願っています。

