

今回の記事では下記のような悩みを解決します。
「LightGBMというワードをよく目にするので、LightGBMについて知りたい」
「LightGBMのpythonでの実装方法が知りたい」
早速解説していきます。
LightGBMとは

LightGBMは2017年にMicrosoftが公開した、「決定木をベースとしたアンサンブル学習」の一つです。
回帰・分類両方に対応しています。
LightGBMは計算速度が速く、予測精度も高いため、kaggleなどの機械学習コンペでも頻繁に出てきます。
決定木についてわからない人は、下記記事で詳細に解説していますのでご活用ください。

次にランダムフォレストとの違いについて簡単に解説します。
ランダムフォレストとの違い
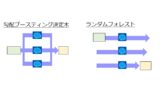
簡単に説明すると、ランダムフォレストは決定木を並列に作って多数決により予測(バギングという手法)するのに対して、
LightGBMは決定木を直列に作って(予測誤差が大きいところのみ学習していく)予測(ブースティングという手法)します。
理解できなくても、「決定木を複数作って予測しているんだな〜」くらいでOKです。
ちなみに私の経験上、ランダムフォレストよりもLightGBMの方が予測精度高いです。
バギングとブースティングは、下記資料にわかりやすく図解されていたので、詳しく知りたい方向けの参考として載せておきます。

上記資料のあるサイトも載せておきます。
LightGBMのイメージは掴めたと思うので、次にpythonでの実装について解説します。
LightGBMの実装

実装の前に、LightGBMはanacondaにデフォルトで入っていないので、インストールする必要があります。(既にインストールされている方は飛ばしていただいて構いません)
LightGBMのインストール
anacondaでのインストールは下記のコードで実行可能です。またダウンロードできない場合は、下記anacondaホームページ参照。
conda install -c conda-forge lightgbm

次にLightGBMでできることについてお話しします。
LightGBMでできること
LightGBMを使用することで、下記のことができます。
・変数重要度の算出
上記2点について、タイタニック予測問題を使用して解説します。
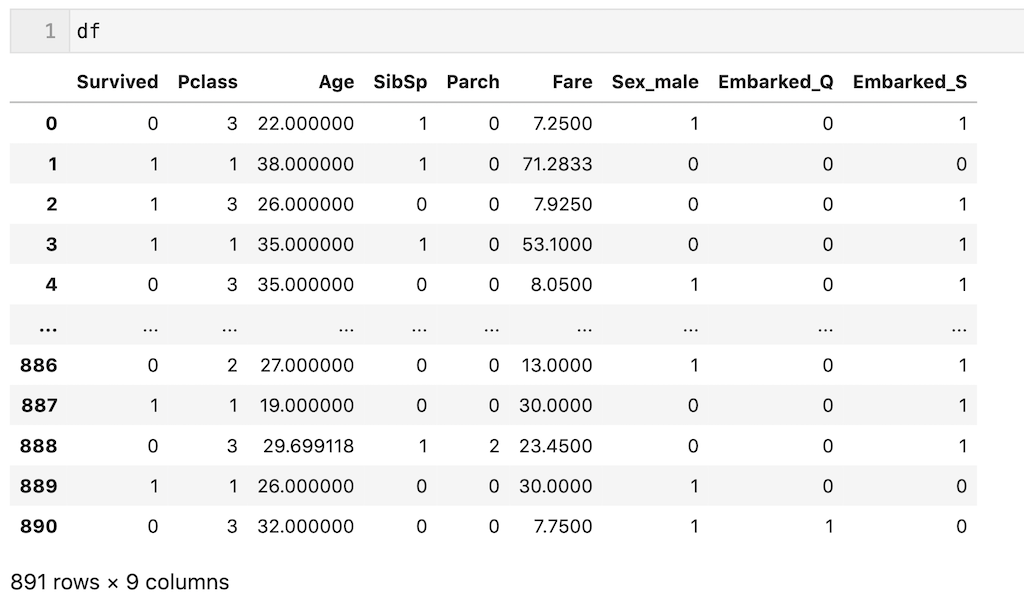
今回は解説を簡単にするために、前処理後のデータ(df)を使用します。一応前処理を簡単に説明すると、’Plass’、’Age’、’SibSp’、’Parch’、’Fare’、’Sex’、’Embarked’の7個の説明変数を使用し、欠損値を平均値、最頻値で補完し、カテゴリカル変数をダミー変数化しています。今回は前処理が目的ではないので、わからなくても全く問題ないです。
dfを下記に示します。
解説のため、dfの700行目までを訓練データ(df_train)、700行目以降をテストデータ(df_test)とします。
df_train = df.iloc[:700, :] df_test = df.iloc[700:, :]
また’Survived’列以外を説明変数(X)、’Survived’列を目的変数(y)とします。それぞれ訓練(train)、テスト(test)としています。
X_train = df_train.drop(columns = ['Survived']) y_train = df_train['Survived'] X_test = df_test.drop(columns = ['Survived']) y_test = df_test['Survived']
データの説明は以上です。
LightGBMの実装方法を早速解説していきます。
LightGBMの学習と予測
LightGBMはTraining APIとScikit-learn APIという2種類、コードの記載方法がありますが、個人的にはScikit-learn APIがわかりやすいと思っているので、Scikit-learn APIの書き方で記載します。(学習はfit、予測はpredictで書くコードの方が慣れている方も多いはず)
モデルの学習は、下記のコードで実装できます。
タイタニック予測問題は分類なのでlightgbm.LGBMClassifierを使用。
回帰の場合はlightgbm.LGBMRegressorを使用すればいい。
import lightgbm as lgb model = lgb.LGBMClassifier() model.fit(X_train, y_train)
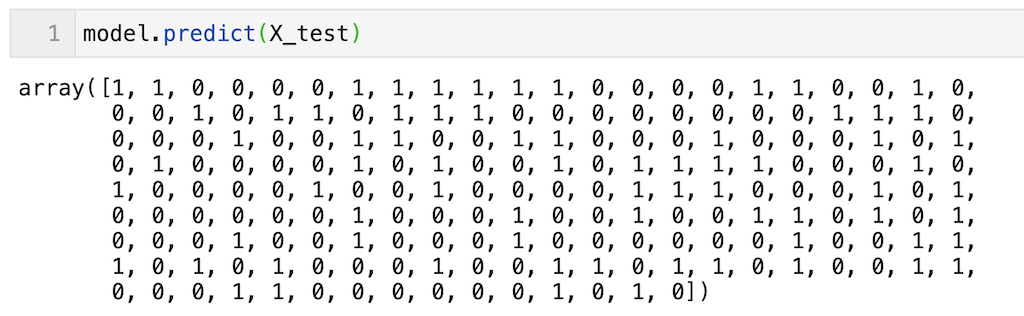
上で学習したモデルを用いて予測する場合はpredictで実装できる。scikit_learnの他のモデルと同じなので使いやすい。
df_testの191個のデータに対する予測(0 or 1が出力されている)を実行できていることが確認できる。
model.predict(X_test)
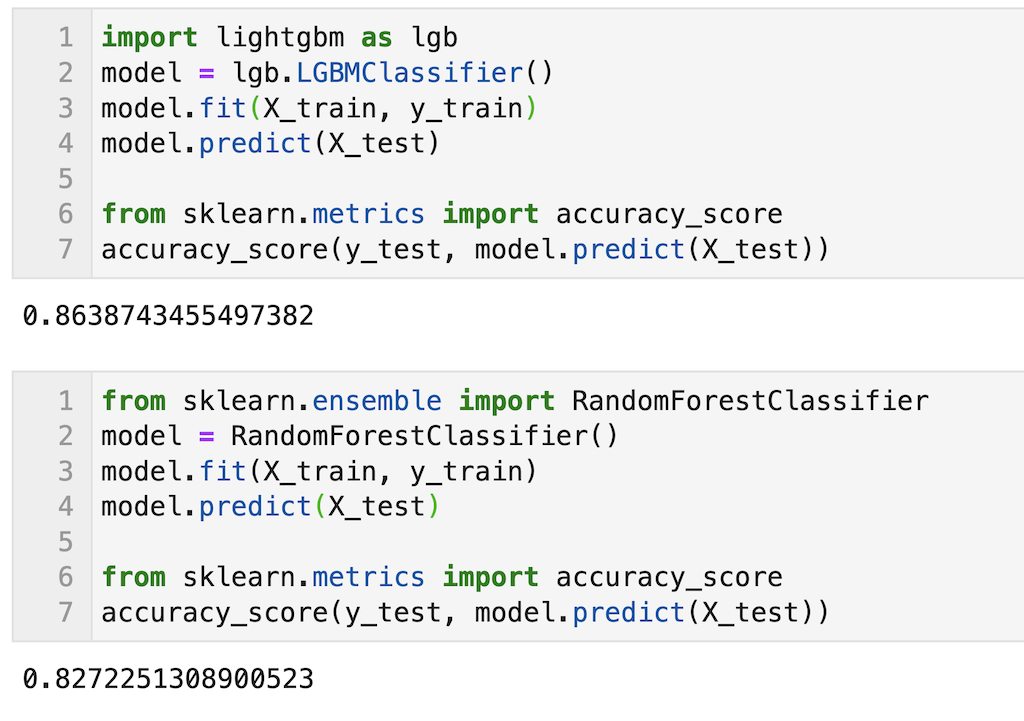
参考程度に同じデータを使ってランダムフォレストを使用した場合と予測精度の比較を示します。
正解率を算出していますが、少しLightGBMの方が精度が高いことが確認できます。ハイパーパラメータを調整してもLightGBMの方が高くなると思います。
LightGBMを使用してモデル構築をする際の特徴量の標準化や正規化について
サポートベクトルマシンやk-NNは特徴量の標準化や正規化が必要ですが、ランダムフォレストやLightGBMは特徴量の標準化や正規化をしなくても問題ない(予測精度に影響はない)です。
なぜなら標準化や正規化をして特徴量の数値が変わっても、相対的な分割境界の位置は変わらないため。ひとまず決定木系のモデルは特徴量の標準化や正規化をしなくても良いということを知っておけばOKです。
続いて参考程度に調整すべきハイパーパラメータについて記載します。
調整すべきハイパーパラメータ
kaggleなどのコンペティションではしっかりハイパーパラメータ調整しないといけないですが、正直LightGBMはデフォルトでもかなり精度出ます。
調整すべきハイパーパラメータは下記記事にわかりやすく纏まったので参考に。

次は重要度の算出について解説します。
重要度の算出
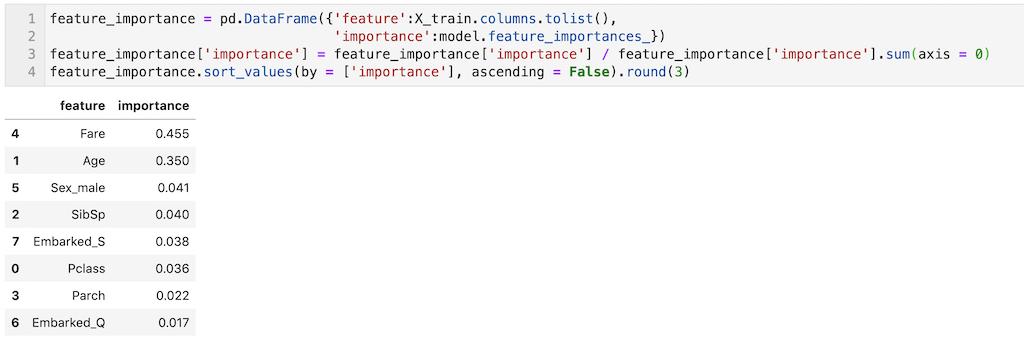
重要度の算出はfeature_importances_で算出できます。今回は構築したモデルをmodelと定義しているため、「model.feature_importances_」と記載すればOK。
model.feature_importances_

これだとわかりにくいので、説明変数と重要度を表形式(pandas dataframe)で出力し、重要度の合計が1になるようにして、変数重要度の大きい順に表記しました。コピペして活用ください!
今回構築したモデルでは’Fare’や’Age’の重要度が大きいことが確認できます。
feature_importance = pd.DataFrame({'feature':X_train.columns.tolist(),
'importance':model.feature_importances_})
feature_importance['importance'] = feature_importance['importance'] / feature_importance['importance'].sum(axis = 0)
feature_importance.sort_values(by = ['importance'], ascending = False).round(3)
変数重要度の注意点
最後に少しだけ注意点を書きます。
変数重要度では説明変数が正・負、どちらに効果があるのかわからない
重回帰分析では偏回帰係数の符号から、その説明変数が正に働いているのか、負に働いているのか、わかるが、変数重要度では正・負、どちらに効果があるのかわかりません。あくまで「どの説明変数が寄与しているのか」くらいしかわかりません。
精度の良いモデルを作らないと変数重要度の議論ができない
変数重要度の大きさは、「モデル構築時にどれだけその説明変数が寄与しているのかという寄与度」であるため、そもそも精度の高いモデルを構築できなければ、変数重要度は意味をなさない。精度の高いモデルであるから変数重要度(どの説明変数が重要なのか)が議論できるようになる。そのため、変数重要度を議論する際は、モデルの精度をしっかり確認してからにしましょう。
LightGBMは非常に強力な機械学習手法でkaggleなどのコンペでも頻繁に使われています。ですので今回の記事で是非LightGBMについて理解を深めてください。
今回の記事はここまでです。最後まで読んでいただきありがとうございます。
✅ LightGBMの回帰問題に挑戦したい方は下記記事もお勧め

✅ 仕事で機械学習を活用してみたい方は私が執筆したnoteもお勧め
サクッと読める分量で機械学習を活用すべき仕事の見つけ方をサクッと解説しています。

皆さんの機械学習の勉強がさらに進み、理解が深まることを願っています。

