

今回の記事は下記のような読者に向けて書いています。
「LightGBMで回帰問題に挑戦したい」
「LightGBMでハイパーパラメータを調整して予測精度を上げる方法を習得したい」
「Optunaの使い方を知りたい」
LightGBMは計算が早く、高い予測精度が得られることからkaggle等のコンペで最も使用されているモデルの1つです。
今回の記事を通して、LightGBMを使って機械学習(回帰問題)に挑戦する一連の流れを是非習得していただければ思います。
LightGBMの基礎・分類問題の実装については下記記事参照。

今回は、「住宅価格予測問題」を使って、「データの前処理、LightGBMでモデル構築、Optunaを使ってハイパーパラメータを調整し予測精度をup」という機械学習(回帰問題)の一連の流れを解説していきます。
まずはデータの読み込みと前処理から解説します。
データの読み込みと前処理

下記のコードで住宅価格予測のデータを読み込み、dfとします。
(下記のコードは覚える必要ないです。コピペしてデータを読み込んでください)
dfは81個の列、1460個のデータからなります。
from sklearn.datasets import fetch_openml import pandas as pd housing = fetch_openml(name="house_prices", as_frame=True) X = housing.data #説明変数 y = housing.target #目的変数 df = pd.concat([X, y], axis = 1)
欠損値処理
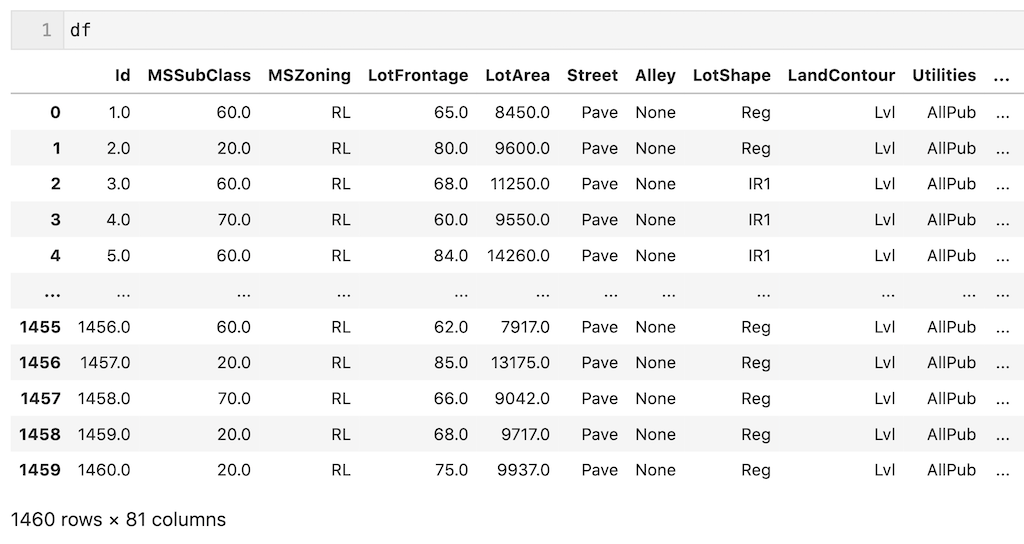
dfを読み込めたので、欠損値の確認をします。
列数が多いので欠損値がある列のみを抽出します。1460個のデータのうちほとんど欠損しているカラムも存在していることが確認できます。
また’Id’は説明変数とは関係ないので最初に削除しておきます。
df = df.drop(columns = ['Id']) df.isnull().sum()[df.isnull().sum() > 0]
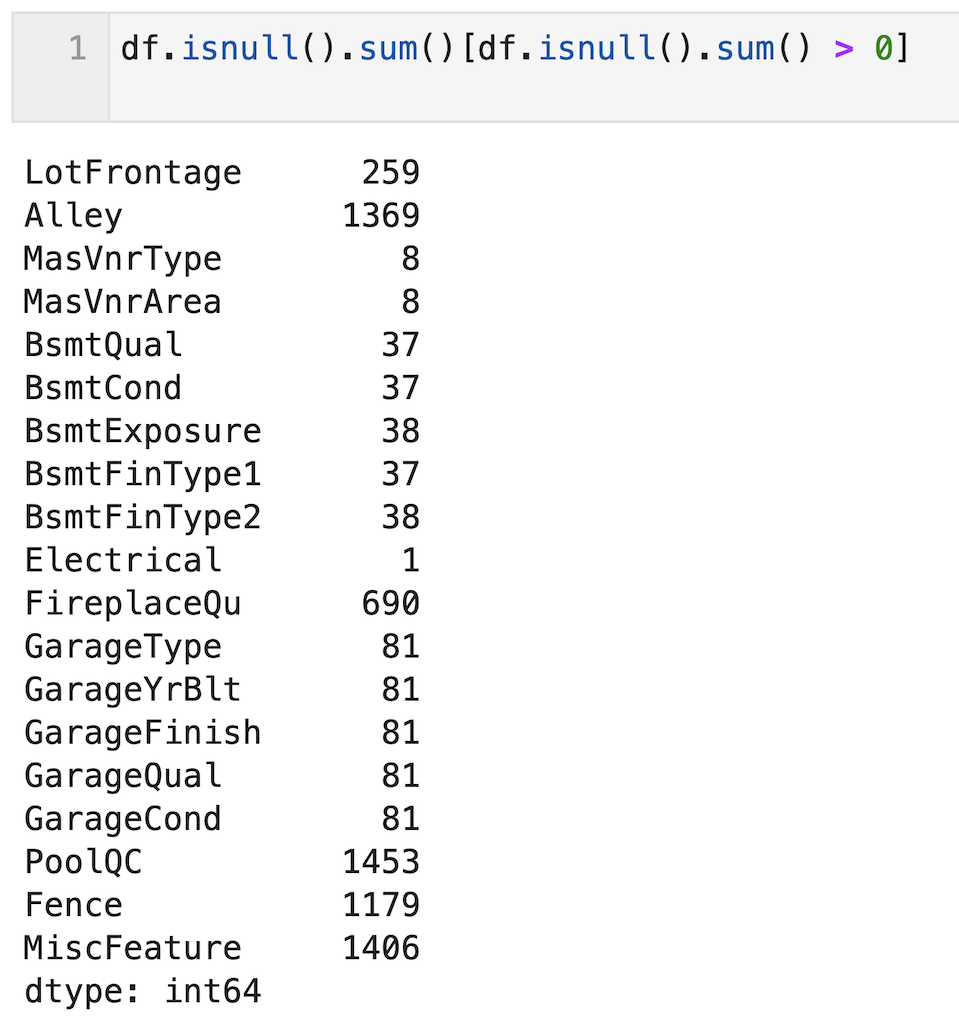
‘Alley’,’FireplaceQu’, ‘PoolQC’, ‘Fence’, ‘MiscFeature’は欠損値が多いので、今回は削除します。
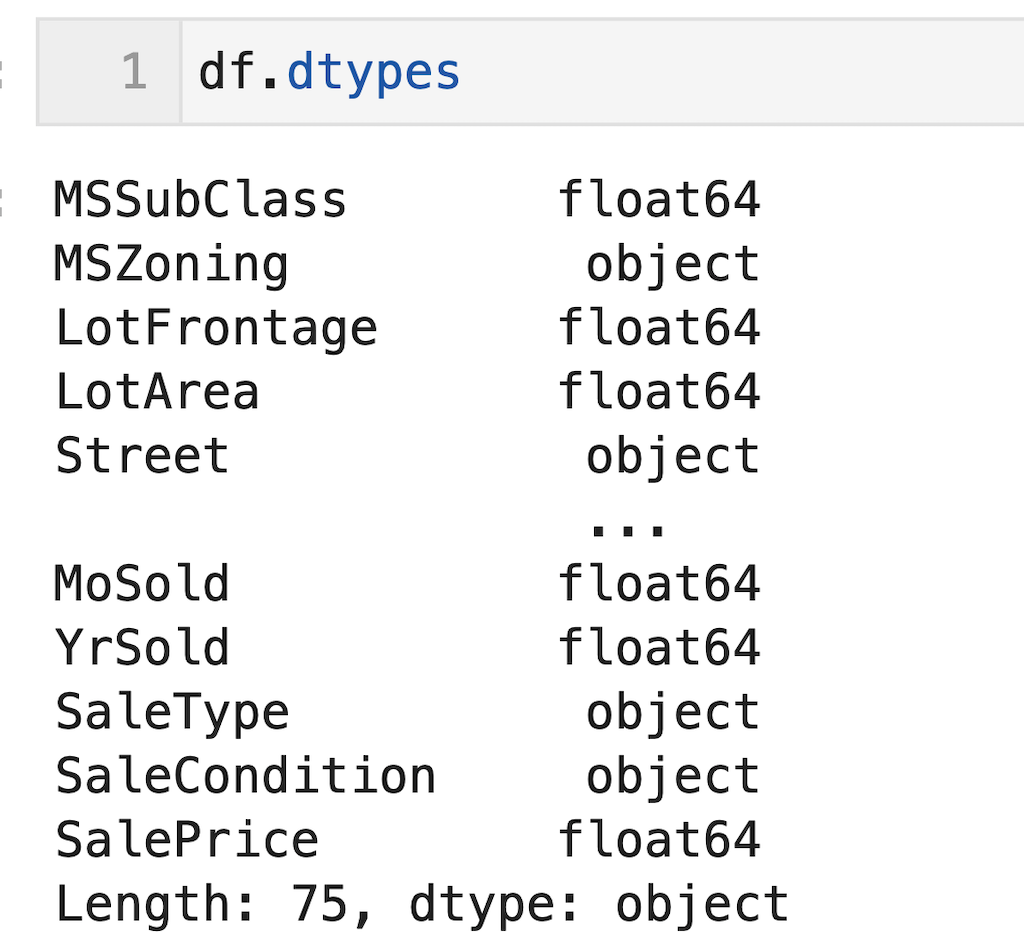
列の削除後、データ型を確認すると、数値データと文字列データ(欠損値があるためobject型と表記されている)が混在していることが確認できます。
df = df.drop(columns = ['Alley','FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature']) df.dtypes
今回は、文字列のデータについては「最頻値」で欠損値を補完し、数値データについては「平均値」で補完します。
下記の「文字列データの欠損値補完のpythonコード」では、dfの’object’型のデータを抽出し、for文で文字列データのカラム名を選択し、欠損値を「最頻値」で補完しています。
df_object = df.select_dtypes(include = ['object'])
df_object_NAN_columns = df_object.isnull().sum()[df_object.isnull().sum() > 0].index
for col in df_object_NAN_columns:
df.loc[df[col].isnull(), col] = df.loc[df[col].isnull(), col].fillna(df[col].mode()[0])
数値データの欠損値補完も同様にして、’int’型、’float’型の列名を抽出し、欠損値がある列を抽出し、for文で欠損値を「平均値」で補完しています。
欠損値補完後、dfには欠損値がないことが確認できます。
df_numerical = df.select_dtypes(include = ['int', 'float64'])
df_numerical_NAN_columns = df_numerical.isnull().sum()[df_numerical.isnull().sum() > 0].index
for col in df_numerical_NAN_columns:
df.loc[df[col].isnull(), col] = df.loc[df[col].isnull(), col].fillna(df[col].mean())

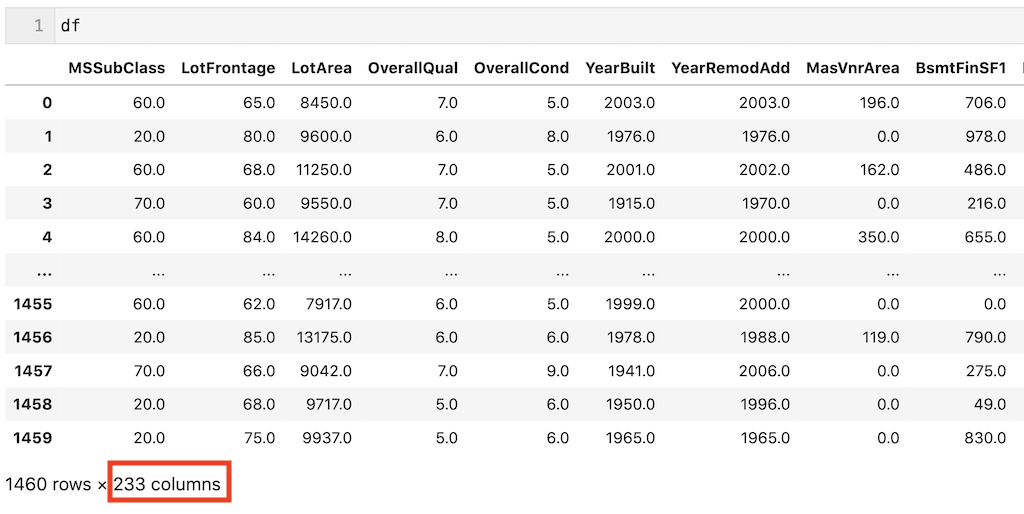
最後に文字列のデータをダミー変数化して欠損値処理は完了。
ダミー変数化して、dfの列数は233個になりました。
df = pd.get_dummies(df, drop_first = True)
続いて目的変数の前処理です。
目的変数については対数変換した値を目的変数(y)として使用します。
対数変換した列名を’log_SalePrice’として、元の ’SalePrice’は削除する。
import numpy as np df['log_SalePrice'] = np.log10(df['SalePrice']) df = df.drop(columns = ['SalePrice'])
前処理が完了したので、LightGBMを使ってモデルを構築していきます。
モデル構築

LightGBMを使ってモデル構築していきます。
まずはハイパーパラメータを調整せずにデフォルトの値でモデル構築し、予測精度を確認します。
下記のコードでは、KFoldを使って10分割交差検証の結果をverificationに格納しています。
予めverificationの’y_test’列に生データを格納しておき、’y_pred’列にlocで行番号を指定して、「LightGBMで構築したモデルの10回分の予測結果」を格納しています。
(機械学習ではKFoldを使った交差検証は頻出なので、是非下記のpythonコードは理解して使えるようにしてください)
r2_scoreを確認したところ、0.889とまずまずの予測精度であることが確認できます。
from sklearn.model_selection import KFold
import lightgbm as lgb
kf = KFold(n_splits = 10, random_state = 42, shuffle = True)
verification = pd.DataFrame()
verification['y_test'] = df['log_SalePrice']
for train_idx, test_idx in kf.split(df):
X_train = df.iloc[train_idx, :-1]
y_train = df.iloc[train_idx, -1]
X_test = df.iloc[test_idx, :-1]
y_test = df.iloc[test_idx, -1]
model = lgb.LGBMRegressor()
model.fit(X_train, y_train)
verification.loc[test_idx, 'y_pred'] = model.predict(X_test)
import matplotlib.pyplot as plt
plt.figure(figsize=(5,5))
plt.scatter(verification['y_test'], verification['y_pred']) # 散布図を描画
plt.show()
from sklearn.metrics import r2_score
r2_score(verification['y_test'], verification['y_pred'])
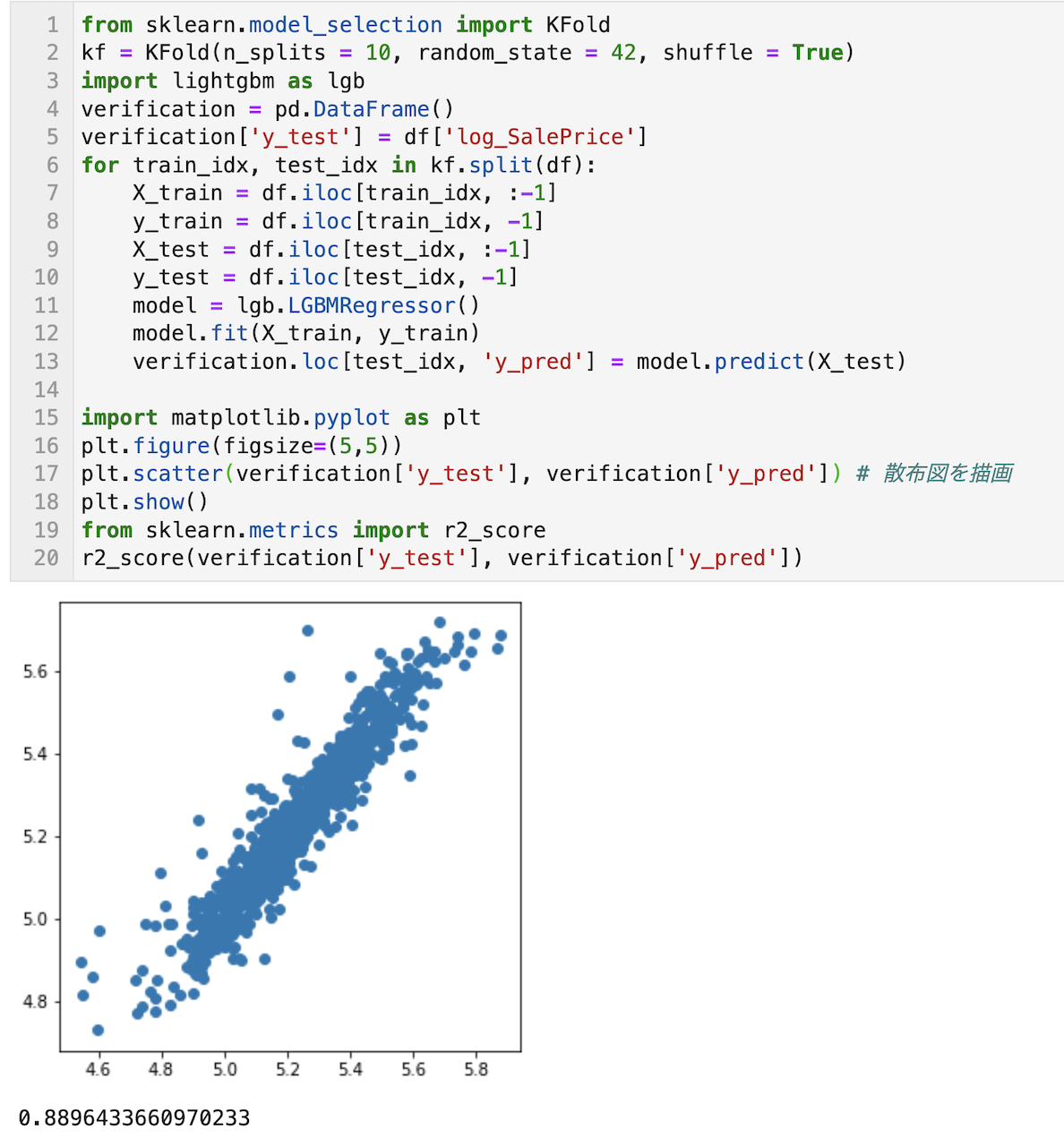
上記のコード(KFold交差検証)は、下記記事で図解しているので、良ければご活用ください。

次に今回はさらなる予測精度upに向けて、LightGBMのハイパーパラメータを調整してみます。
LightGBMのハイパーパラメータの調整

LightGBMの調整すべきハイパーパラメータについては下記記事参照。

今回は上記の記事に倣って、下記の7個のハイパーパラメータを調整していきます。
それぞれLightGBMのScikit-learn APIでパラメータ名を記載しています。
・reg_lambda(float型)
・num_leaves(int型)
・colsample_bytree(float型)
・subsample(float型)
・subsample_freq(int型)
・min_child_samples(int型)
max_depth(int型)やn_estimators(int型)もありますが、計算に膨大な時間がかかったため、今回はこれら7個のハイパーパラメータを最適化します。
(理想を言うと、全てのハイパーパラメータを調整した方がいいです。予測精度が高くなります。調整しないと、デフォルトの数値で固定されるからです。ハイスペックPCをお持ちの方は是非試してみてください。)
今回はOptunaを使って、LightGBMのハイパーパラメータを調整していこうと思います。
Optunaとは
OptunaはPrefferedNetworks社が開発した、ハイパーパラメータの自動最適化フレームワークで、効率的にハイパーパラメータを最適化できます。
調整するハイパーパラメータと探索範囲を指定して、自身で設定した評価指標(今回であればr2_score)が最大 or 最小となるハイパーパラメータを探索します。
探索する際、ベイズ最適化という手法を活用し、少ない探索回数で最適なハイパーパラメータを探索できます。
特にLightGBMのようにハイパーパラメータが多い時に重宝します。
Optunaはanacondaにデフォルトで入っていないので、インストールが必要です。
下記コードを使ってインストールしてください。
conda install conda-forge::optuna
またインストールできない場合は下記サイトを参考にしてください。

Optunaをインストールできたと思うので、実際にOptunaを使ってLightGBMのハイパーパラメータを最適化していきます。
Optunaを使ったLightGBMのハイパーパラメータ最適化
下記コードでは、params(タプル)に調整すべきハイパーパラメータと探索範囲を指定して、modelにparamsを渡して学習・予測し、検証結果(r2_score)が最大(direction=’maximize’)となるハイパーパラメータを決定しています。今回は150回(n_trials = 150)計算して最適なパラメータを決定しています。
またparamsに0を入力するとエラーが出るので1e-8としています。
(ハイパーパラメータの探索は計算に時間がかかるため、単に訓練データと検証データに分割(例えば8:2とか)して、r2_scoreを最大化するハイパーパラメータを決定することもある。今回はデータ数が約1500個とそこまで多くないため、分割交差検証によりr2_scoreを算出し、ハイパーパラメータを決定した)
import optuna
def objective(trial):
params = {
'reg_alpha': trial.suggest_float('reg_alpha', 1e-8, 10.0, log = True),
'reg_lambda': trial.suggest_float('reg_lambda', 1e-8, 10.0, log = True),
'num_leaves': trial.suggest_int('num_leaves', 2, 1000),
'colsample_bytree': trial.suggest_float('colsample _bytree', 1e-8, 1.0),
'subsample': trial.suggest_float('subsample', 1e-8, 1.0),
'subsample_freq': trial.suggest_int('subsample_freq', 1, 100),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 1000)
}
from sklearn.model_selection import KFold
kf = KFold(n_splits = 10, random_state = 0, shuffle = True)
import lightgbm as lgb
verification = pd.DataFrame()
verification['y_test'] = df['log_SalePrice']
for train_idx, test_idx in kf.split(df):
X_train = df.iloc[train_idx, :-1]
y_train = df.iloc[train_idx, -1]
X_test = df.iloc[test_idx, :-1]
y_test = df.iloc[test_idx, -1]
model = lgb.LGBMRegressor(**params)
model.fit(X_train, y_train)
verification.loc[test_idx, 'y_pred'] = model.predict(X_test)
return r2_score(verification['y_test'], verification['y_pred'])
sampler = optuna.samplers.TPESampler(seed=0)
study = optuna.create_study(sampler = sampler, direction='maximize')
study.optimize(objective, n_trials = 150)
Optunaで得られたハイパーパラメータの値を用いて、再度10分割交差検証により予測精度を確認。
r2_scoreが0.896に向上していることが確認できる。
from sklearn.model_selection import KFold
kf = KFold(n_splits = 10, random_state = 42, shuffle = True)
import lightgbm as lgb
verification = pd.DataFrame()
verification['y_test'] = df['log_SalePrice']
for train_idx, test_idx in kf.split(df):
X_train = df.iloc[train_idx, :-1]
y_train = df.iloc[train_idx, -1]
X_test = df.iloc[test_idx, :-1]
y_test = df.iloc[test_idx, -1]
model = lgb.LGBMRegressor(reg_alpha = 0.01302208357906488,
reg_lambda = 0.8988145921821439,
num_leaves = 957,
colsample_bytree = 0.38389986119037844,
subsample = 0.9988314486605718,
subsample_freq = 40,
min_child_samples = 26
)
model.fit(X_train, y_train)
verification.loc[test_idx, 'y_pred'] = model.predict(X_test)
import matplotlib.pyplot as plt plt.figure(figsize=(5,5)) plt.scatter(verification['y_test'], verification['y_pred']) plt.show() from sklearn.metrics import r2_score r2_score(verification['y_test'], verification['y_pred'])
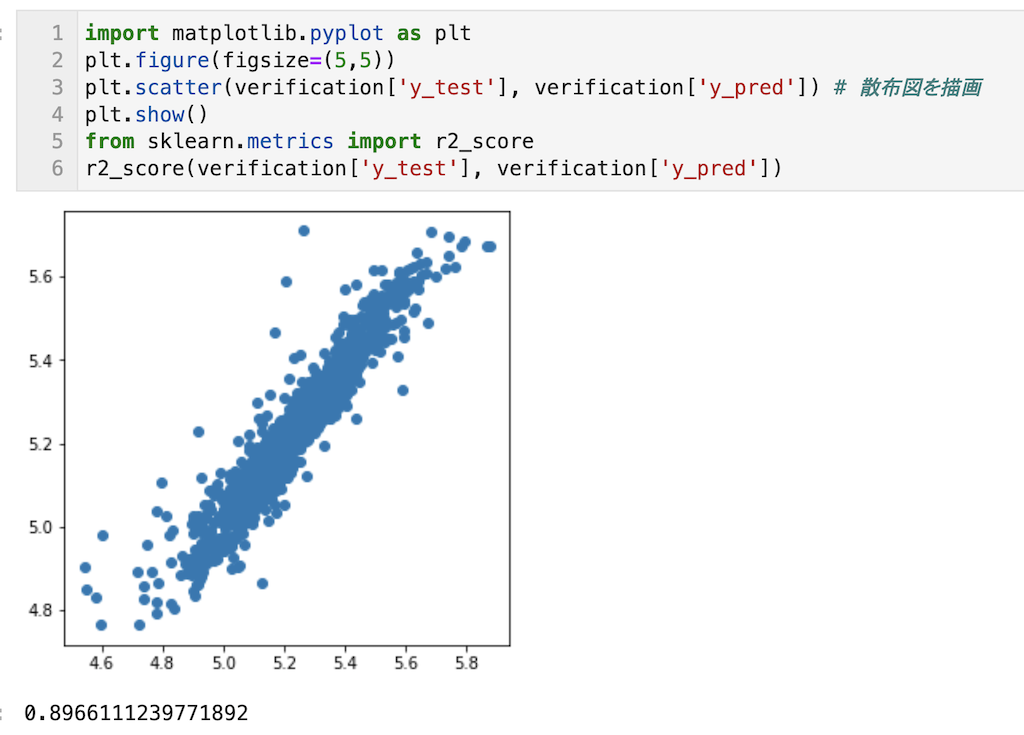
ハイパーパラメータを最適化し予測精度が問題なければ、あとは全データを使ってモデル構築し、実際に予測で活用していくという流れになります。
今回の記事はここまでです。
LightGBM等のハイパーパラメータが多いモデルは、よくoptunaを使用してハイパーパラメータを調整するので是非今回の記事で使い方をマスターしてください。
この記事が理解できれば、kaggle等のコンペにも参加できると思います!
今回は10分割交差検証で精度検証しているため、普段よりpythonコードが長くなっていますが、一つ一つ分解してjupyter notebookで実行しながらコードの意味を理解するのに使っていただければと思います。pythonコードは汎用的な書き方にしているので、他でも応用が効くはずです。
また、今回の記事のpythonコードは覚える必要はないです。
必要になればこの記事を再確認して、pythonコードをコピペして活用してもらえればと思います。
✅ 機械学習の「全体像」を知りたい人は下記記事がお勧め
研究開発で4年・1人で機械学習を活用してみて理解した機械学習の全体像を全部書きました。
3万字まで文字を削って、一冊に纏め切りました。
専門書を買う前に、これを読んで機械学習の「全体像」を理解してほしいです!

✅ 仕事(研究開発)で機械学習を活用したい・し始めた人は下記記事もお勧め
私が機械学習を独学して、いざ仕事(研究開発)で機械学習を活用し始めた際に失敗したこと、失敗から学んだことを書いています。
機械学習を独学すればするほど、「やってしまいがち!」だと思っています。
現に私は失敗しました。。

私の失敗から学んでいただいて、仕事でも良いスタートダッシュを切れることを願っています。
皆さんの機械学習の勉強がさらに進み、理解が深まることを願っています。

