

Pythonのpandas DataFrameでこんな悩みはありませんか?
「Pandas DataFrameで重複データを確認したい、、しかしやり方がわからない。」
「Pandas DataFrameで重複データを削除したい、、しかしやり方がわからない。」
そのお悩み解決します。
Pandasのduplicated( )メソッドを活用することで重複データの確認ができます。
また、Pandasのdrop_duplicates( )メソッドを活用することで重複データの削除ができます。
下記のようなpandas dataframe(以下dfと表記)を使用して、解説していきます。
#dfを作成
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Alice', 'David','Alice'],
'Age': [24, 30, 24, 10, 15],
'height':[150, 175, 150, 150, 145]
})
df #dfを出力
Pandasのduplicated( )メソッドの使い方

pandasのduplicated( )メソッドを使用することで、データセット内で重複している行を識別することができます。
基本的な使い方は下記のようになります。
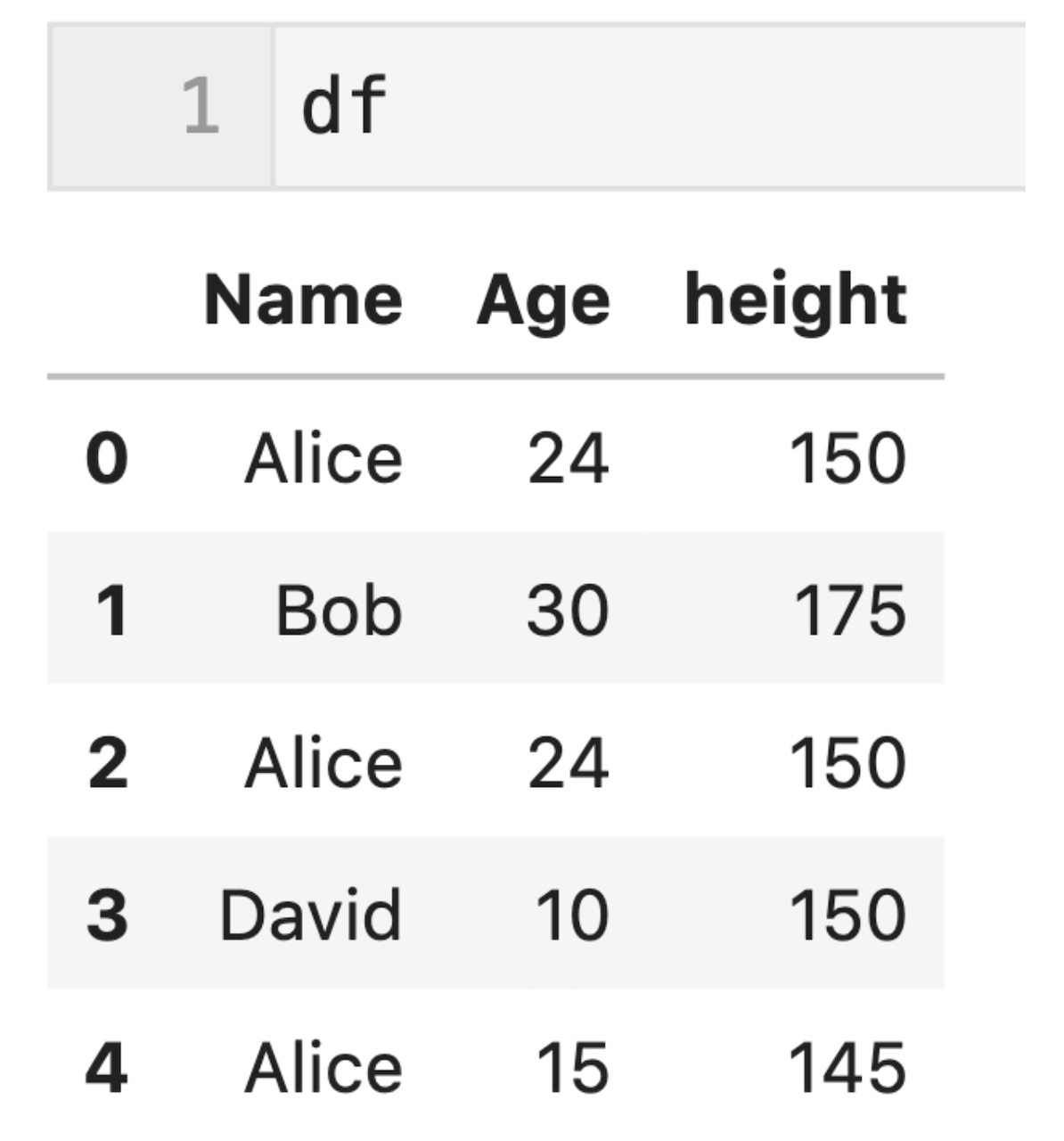
デフォルトでは、重複の判断は「行の全ての要素が同じであれば重複」と判断されます。
今回は0行目と2行目の要素が全て同じであるため、2行目が重複データ(True)と表示されます。
(0行目は重複データと判定されません。)
df.duplicated( )

「keep = False」とすることで、重複する全ての行をTrueとして表示できる。
引数keep = Falseとすることで重複している行全てをTrueと表示できます。
今回は0行目と2行目が重複しているので、0行目と2行目がTrueになります。
df.duplicated(keep = False)
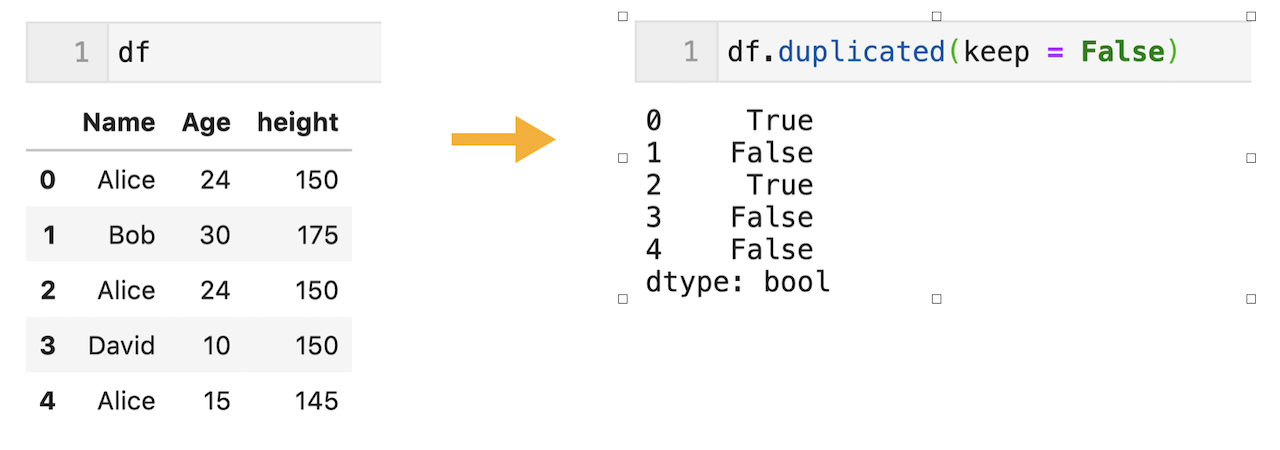
bool型を活用して、重複しているデータのみを抽出することが可能。
bool型を活用することで、重複データ(0行目と2行目)を抽出できます。
df[df.duplicated(keep = False)]
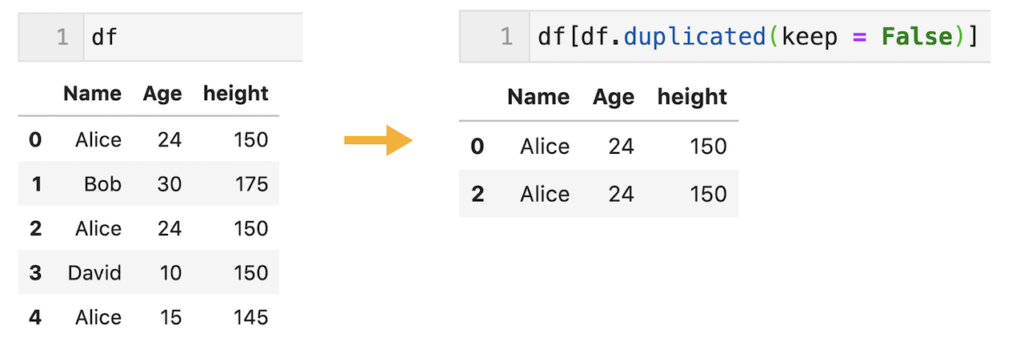
特定の列の要素が同じかどうかで重複を判断することも可能
デフォルトでは行内の全ての要素が同じであるかどうかで重複を判断するが、引数subsetを設定することで、「特定の列の要素が同じかどうかで重複を判断」することも可能。
今回は’Name’列の要素が同じかどうかで重複を判断しています。
‘Name’が’Alice’の2,4行目がTrueとして表示されています。
df.duplicated(subset = ['Name'])
複数の列の要素が同じかどうかで重複を判断したい場合はsubset = [ ]の中に複数の列名を記載すればいい。
今回の場合、例えば、subset = [‘Name’, ‘height’]とすれば、この2つの要素が等しい行が重複(True)と表示されます。
次にpandasのdrop_duplicates( ) の使い方を解説します。
pandasのdrop_duplicates( )の使い方

pandasのdrop_duplicates( )メソッドを使用することで、データセット内で重複している行を削除することができます。
重複の判断、引数の設定はduplicated()メソッドと同じです。
基本は下記のように記載します。
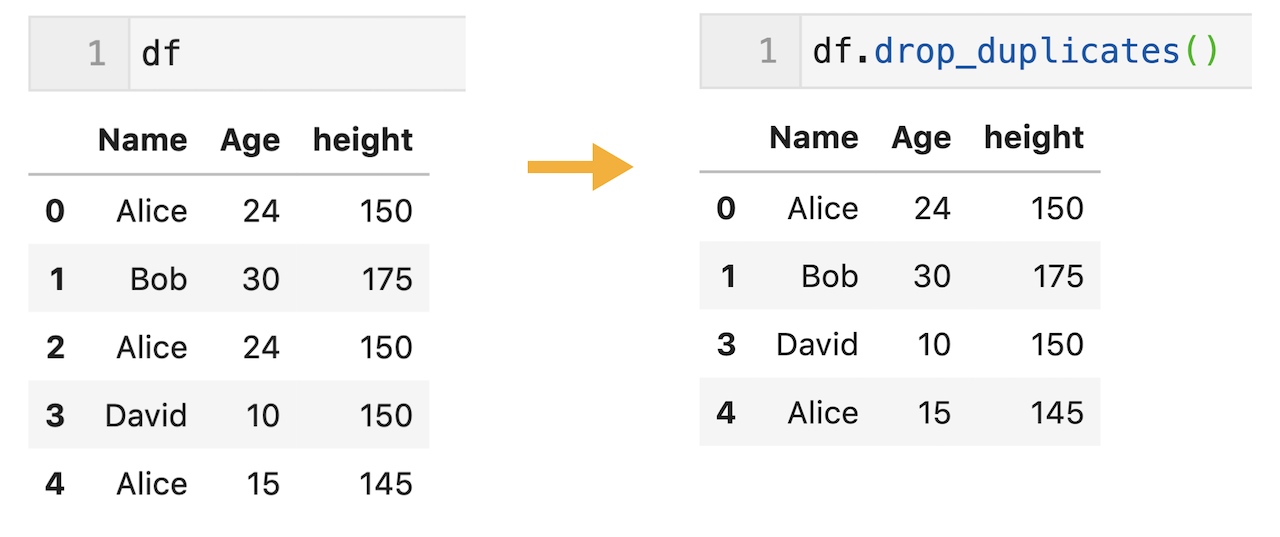
dfは0行目と2行目が全て同じ要素なので、2行目が重複行になります。そのため、drop_duplicates( )メソッドで2行目が削除されます。
df.drop_duplicates( )
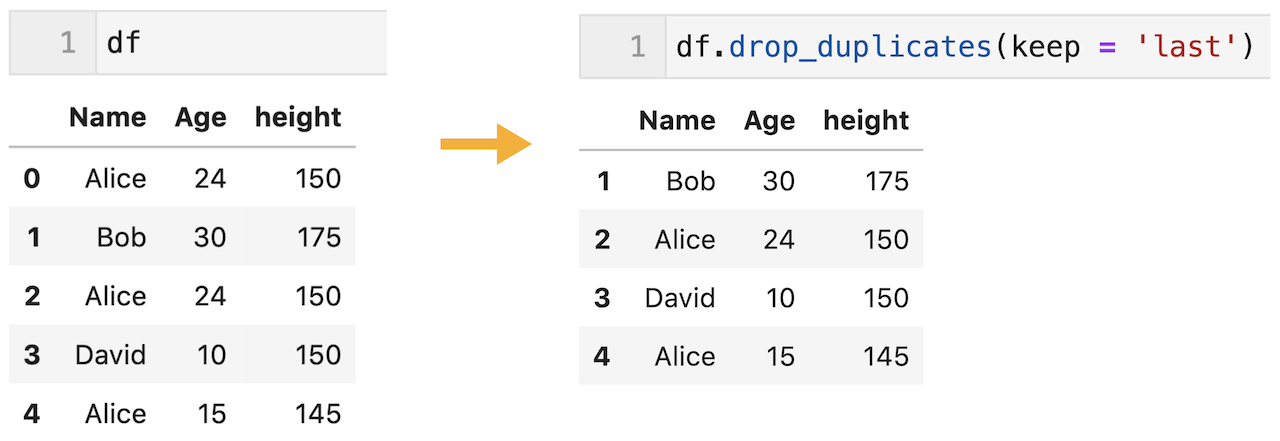
重複行の削除ですが、keep = ‘last’とすることで、後の行を残し、前の行を削除することもできます。
下のコードでは0行目が削除されていることが確認できます。
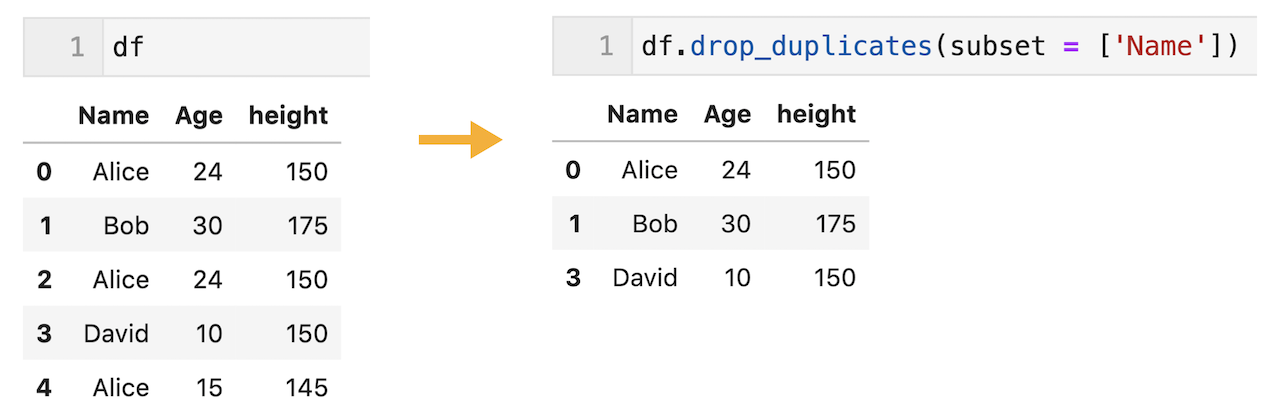
特定の列の要素が同じかどうかで重複を判断することも可能
duplicated( )メソッドと同様に、引数subsetを設定することで、特定の列の要素が同じかどうかで重複を判断することもできます。
df.drop_duplicates(subset = ['Name'])
複数の列の要素が同じかどうかで重複を判断したい場合は、subset = [ ]の中に複数の列名を記載すればいい。
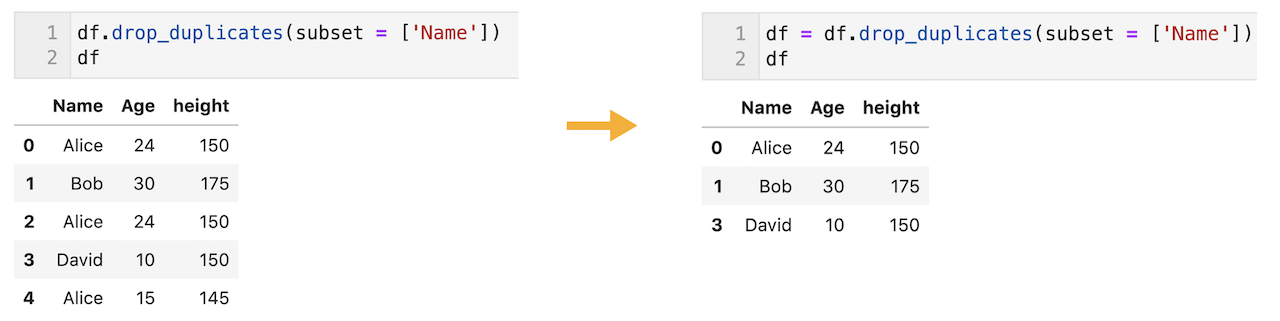
dfを更新しないと、重複データの削除がdfに反映されない
下記のようにdf.drop_duplicates(subset = [‘Name’])を実行してdfを出力しても、重複データが削除されていない。(下図左側)
重複データの削除をdfに反映させるためには、「重複データ削除後のdf」をdfとする必要がある。
以下のようにdf = df.drop_duplicates(subset = [‘Name’])とdfを更新することで、df内の2、4行目が削除されていることが確認できます。(下図右側)
データの削除後は、「index番号のリセット」をしないと、後工程でエラーが発生する可能性が高いので忘れないようにしてください。
下記記事参照。

本記事はここまでです。最後まで読んでいただきありがとうございました。
今回は、pythonのPandas DataFrameで重複行を確認・削除する方法を解説しました。
特にpandasのduplicated( )メソッドとdrop_duplicates( )メソッドの使い方について解説しました。
pythonを活用したデータサイエンスでは、データの確認ができないと正しい解析ができないので、
是非ともこの記事を通してマスターしていただければと思います。

