

今回の記事では下記の悩みを解消します。
「Pandas DataFrameでキーを基にデータを結合する方法がわからない」
「Pandasのmerge( )関数でデータがどのように結合されているのかイメージできない」
「Pandasのmerge( )関数の使い方がわからない」
こんな悩みを解決していきます。
今回の記事では、Pandas DataFrameでキーを基にデータを結合する方法(merge関数)について解説していきます。
キーを用いず結合する場合(pandas concat( )関数の使い方)は下記記事参照

pythonを活用したデータサイエンスでは、キーを用いてデータを結合することは頻出ですので、是非、今回の記事で理解してほしいです!
早速解説していきます。
Pandas merge( )関数の使い方
Pandasのmerge( )関数を使用することで、キーを用いてデータを結合できます。
文字列(str)、数値(int, float)、ブール値(True, False) など、さまざまなデータ型をキーとして使用できます。
結合の仕方は下記の4種類あり、それぞれ解説していきます。
・外部結合
・左結合
・右結合
今回はタイタニック予測問題データを使って解説していきます。データはkaggleのホームページからダウンロードできます。

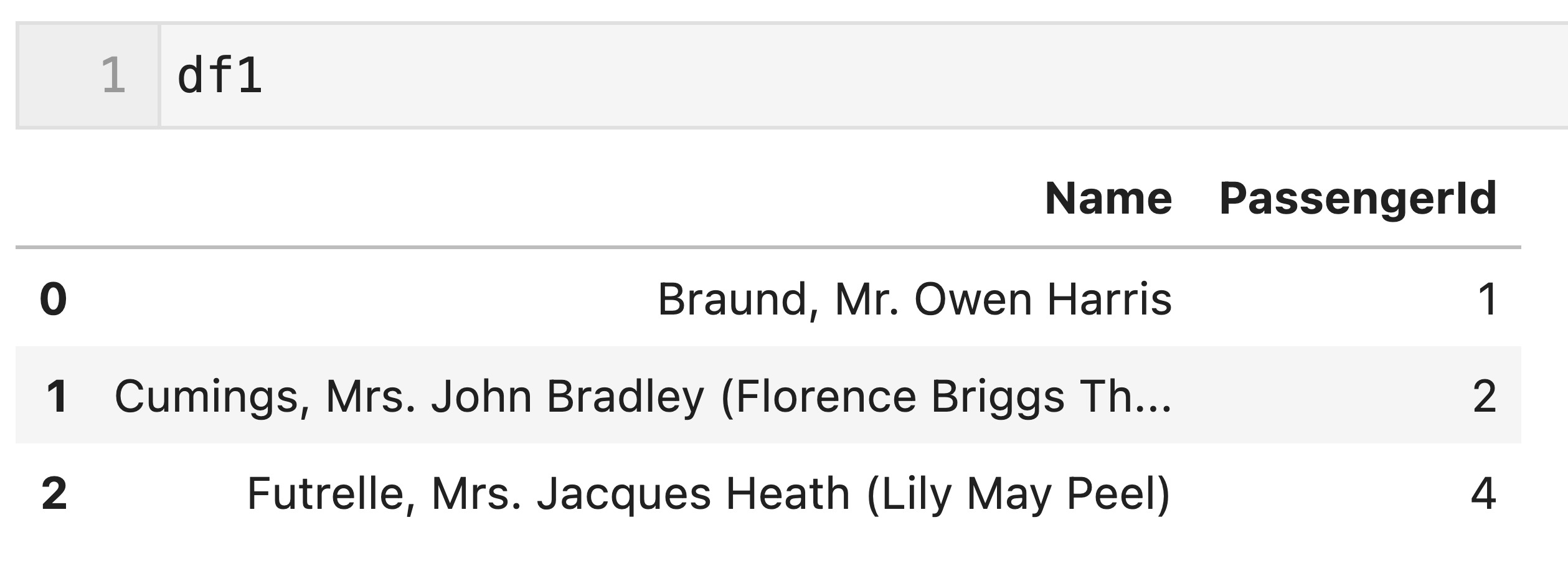
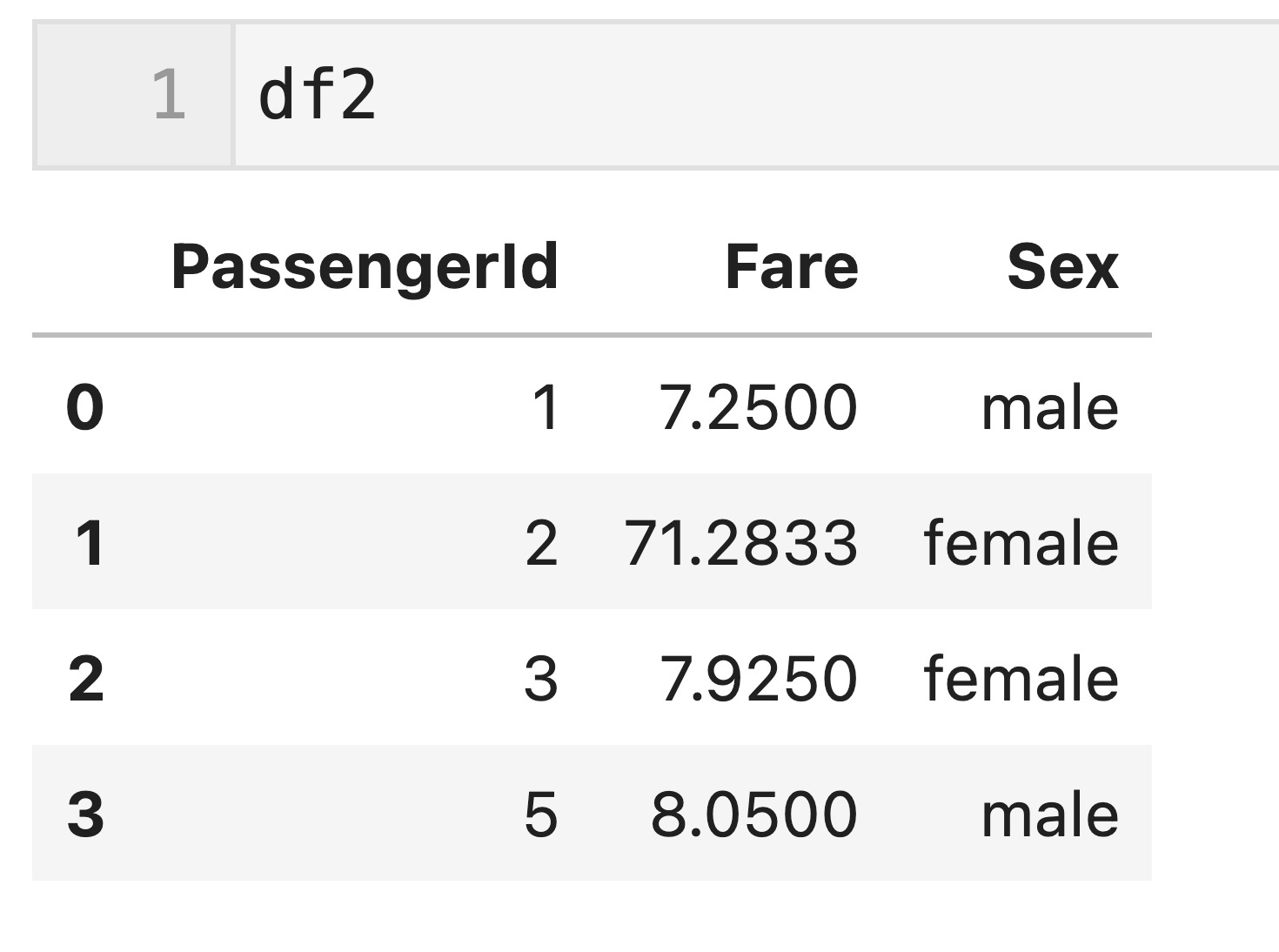
train.csvをdfとして読み込んで、下記のdf1とdf2を使って、キー(’PassengerId’列の値)を基に結合してみたいと思います。
df1とdf2は、’PassengerId’列の値「1, 2」が共通しており、「3, 4, 5」が共通していないです。
df1 = df[['Name','PassengerId']].iloc[[0,1,3], :].reset_index(drop = True) df2 = df[['PassengerId', 'Fare','Sex']].iloc[[0,1,2,4], :].reset_index(drop = True)
まずは内部結合から解説していきます。
内部結合
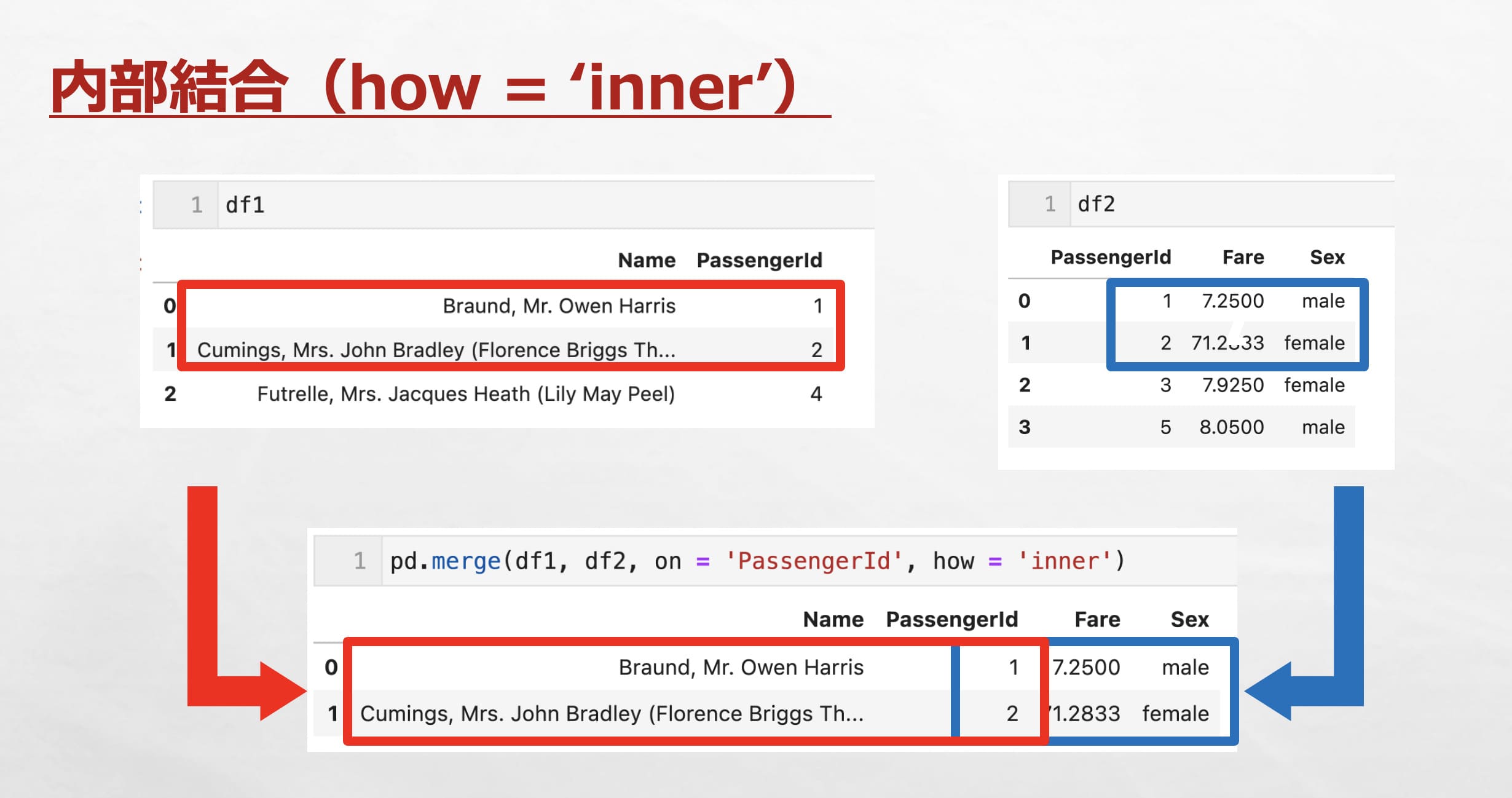
内部結合は、共通のキーを持つ行だけを結合する方法で、共通のキーがない行は、結合結果には含まれません。
『how = ‘inner’』とすることで内部結合できます。
(merge( )関数はデフォルトで内部結合を実行するので、『how = 』の設定はしなくても問題ないです)
df1とdf2を内部結合すると、共通のキーがある行(’PassengerId’列の値が「1, 2」の行)が結合されます。df1とdf2で共通のキーがない行(’PassengerId’列の値が「3, 4, 5」の行)は結合後のデータには含まれません。
また、『on = ‘PassengerId’』で’PassengerId’列をキー列に設定しています。
pd.merge(df1, df2, on = 'PassengerId', how = 'inner')
続いて外部結合について解説していきます。
外部結合
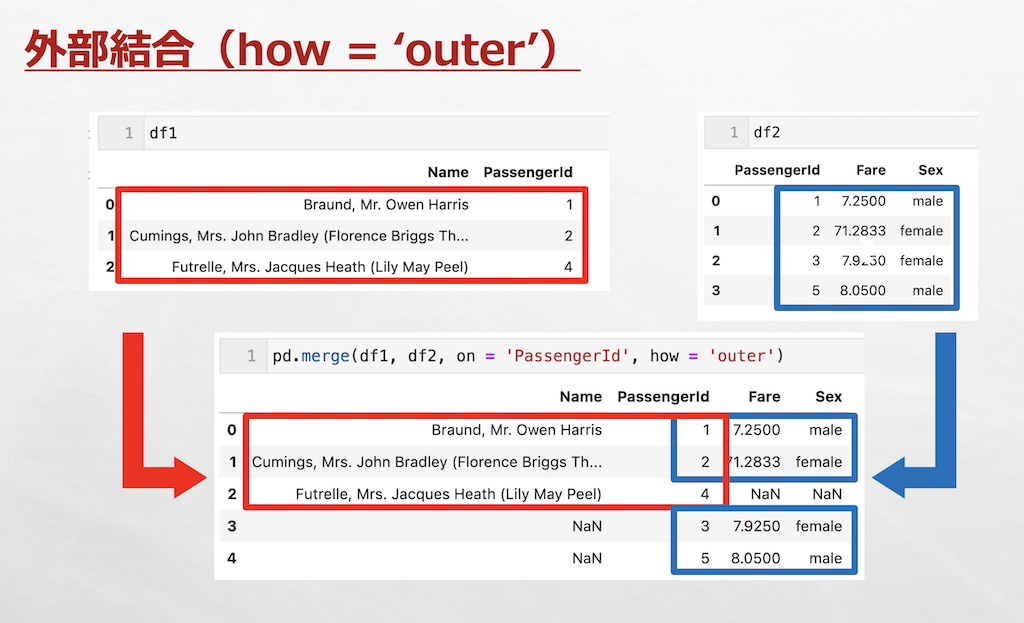
外部結合は、両方のデータフレームに存在するすべてのキーを保持して結合します。
『how = ‘outer’』とすることで外部結合できます。
df1とdf2を外部結合すると、共通のキーがある行(’PassengerId’列の値が「1, 2」の行)が結合され、共通のキーがない行(’PassengerId’列の値が「3, 4, 5」の行)も保持されます。データがないところはNaN(欠損値)となります。
pd.merge(df1, df2, on = 'PassengerId', how = 'outer')
続いて左結合を解説していきます。
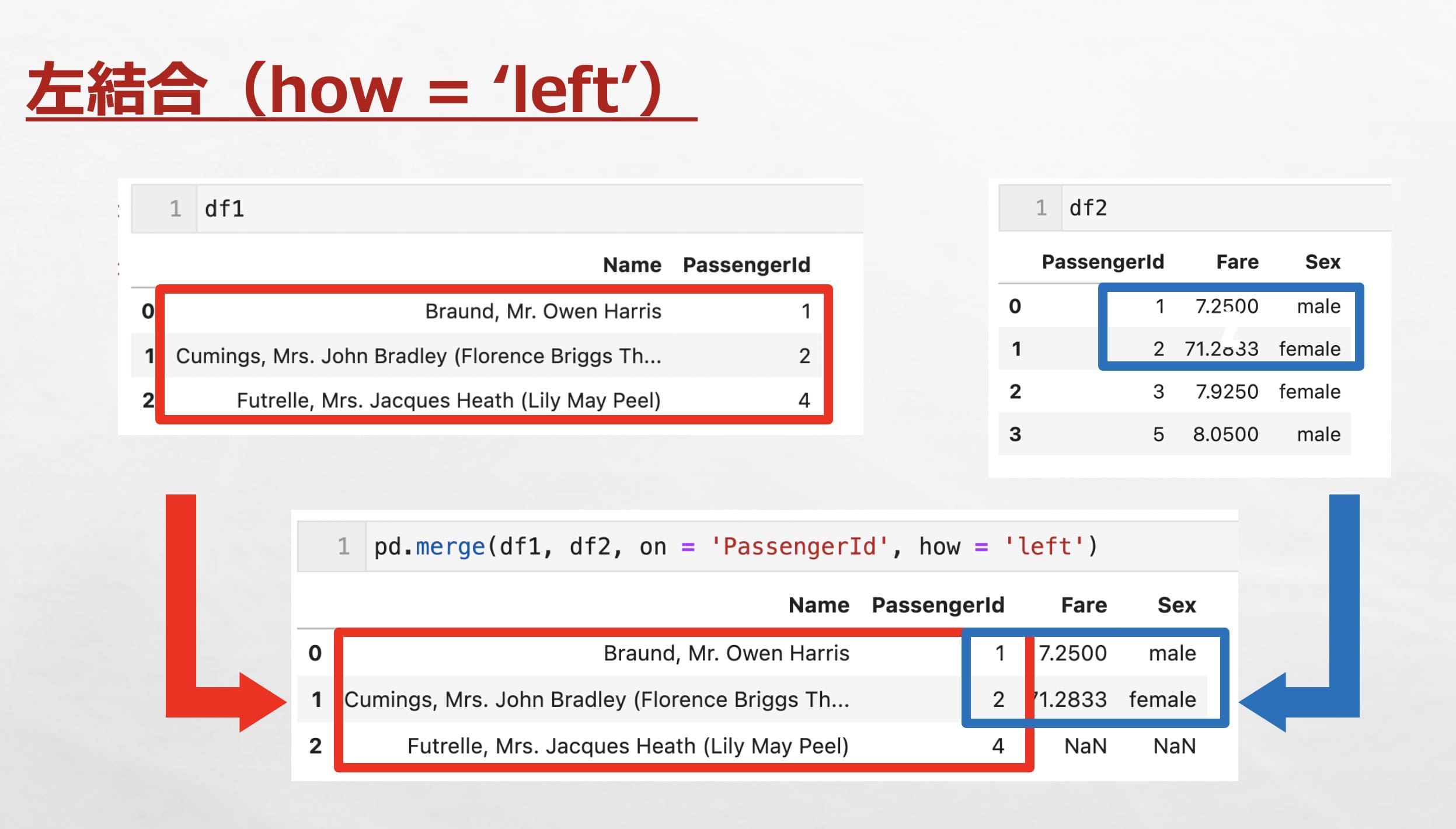
左結合
左結合は、左側のデータフレームのすべての行を保持しつつ、右側のデータフレームと共通するキーに基づいてデータを結合する方法です。右側のデータフレームに対応するキーが存在しない場合、その部分はNaNで補填されます。
『how = ‘left’』とすることで左結合できます。
df1とdf2を左結合すると、左(今回はdf1)のデータが全て残り、df2の共通のキーがある行(’PassengerId’列の値が「1, 2」の行)が結合されます。共通するキーがない箇所はNaNとなります。
pd.merge(df1, df2, on = 'PassengerId', how = 'left')
続いて右結合を解説していきます。
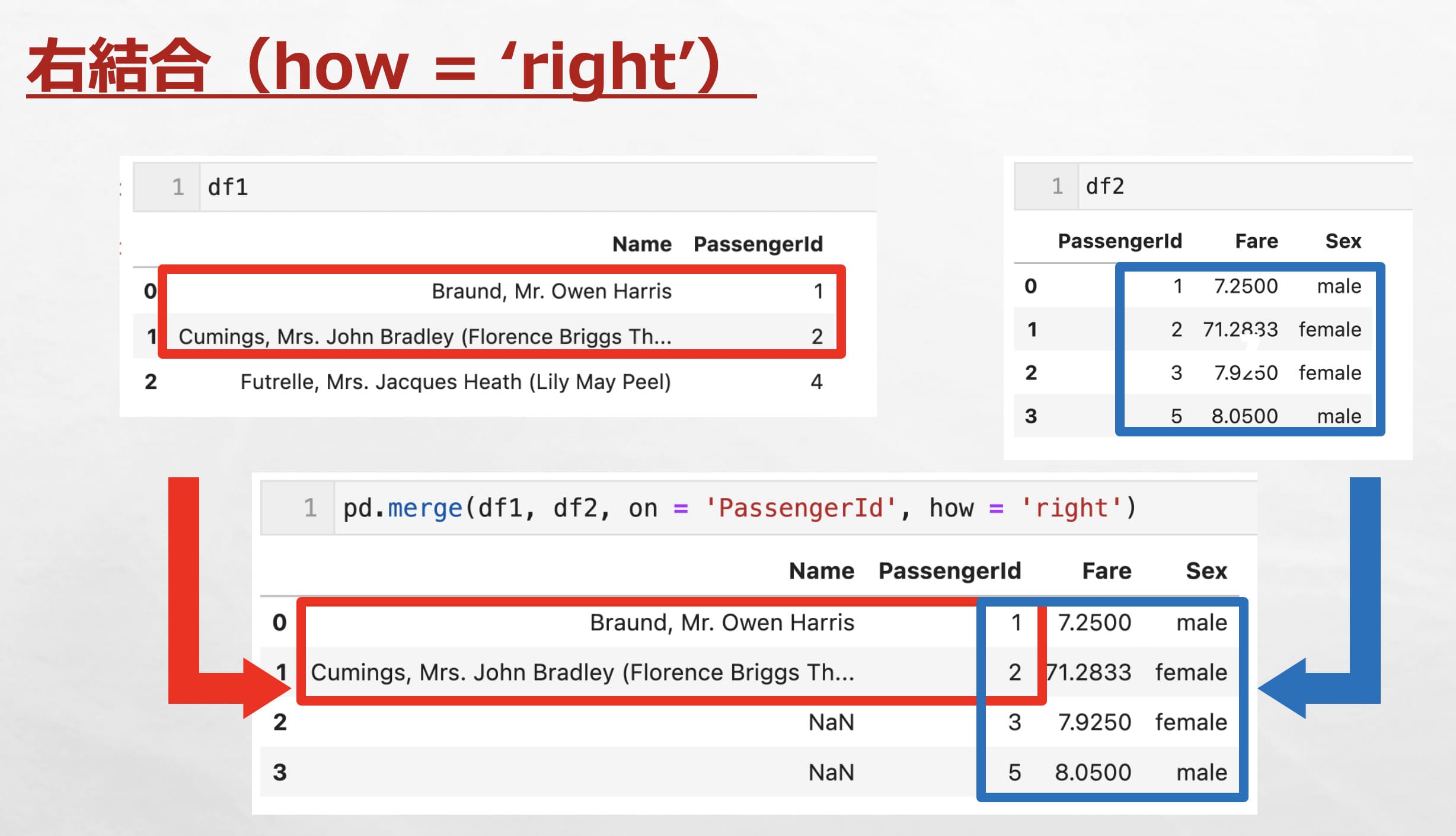
右結合
右結合は先ほどの左結合を右にしただけです。
『how = ‘right’』とすることで右結合できます。
df1とdf2を右結合すると、右(今回はdf2)のデータが全て残り、df1の共通のキーがある行(’PassengerId’列の値が「1, 2」の行)が結合されます。共通するキーがないデータはNaNとなります。
pd.merge(df1, df2, on = 'PassengerId', how = 'right')
次は結合するデータフレームでキー列の名称が異なる場合について解説していきます。
結合するデータフレームでキー列の名称が異なる場合
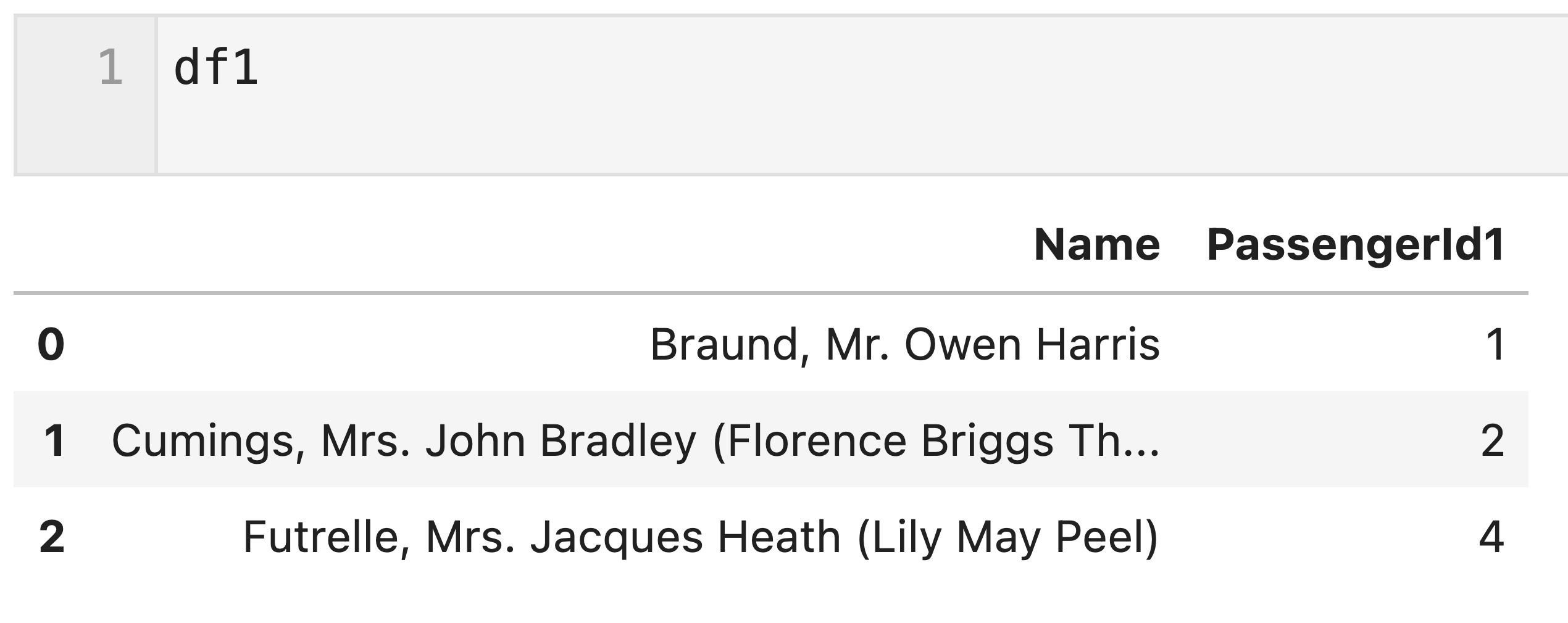
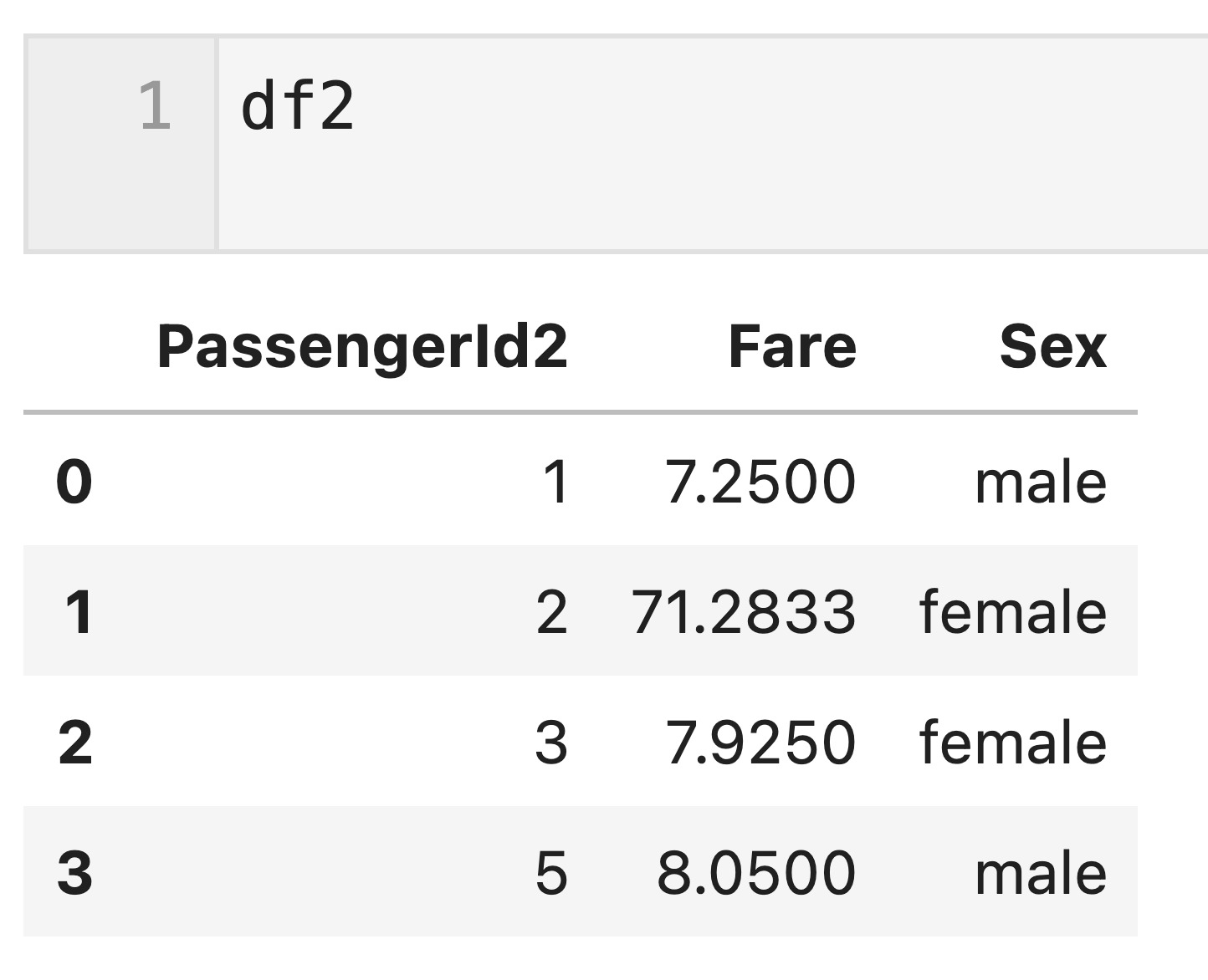
df1とdf2それぞれの’PassengerId’列の名称を’PassengerId1’、’PassengerId2’として内部結合してみます。
df1 = df1.rename(columns={'PassengerId': 'PassengerId1'})
df2 = df2.rename(columns={'PassengerId': 'PassengerId2'})
キー列の指定を「left_on」、「right_on」とすることで、キー列の名称が異なってもキー列を基に結合できます。
(内部結合以外でも、「left_on」、「right_on」とすれば結合できます)
pd.merge(df1, df2, left_on = 'PassengerId1', right_on = 'PassengerId2' ,how = 'inner')

最後に複数のキーを基に結合する場合を解説します。
複数のキーを基に結合する方法
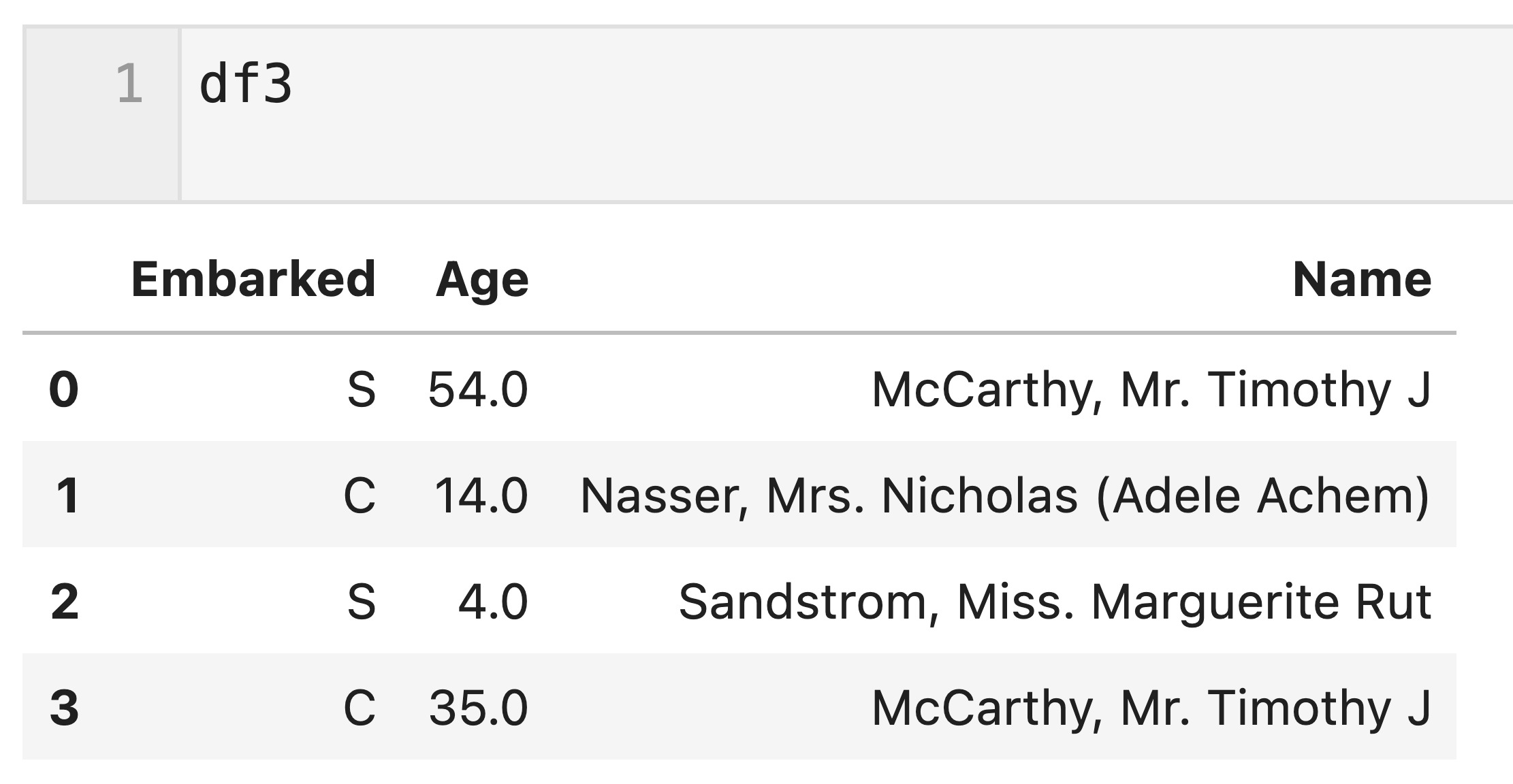
下記のdf3とdf4を使って複数のキー(’Name’列、’Age’列の値)を基に結合してみます。
df3は0,4行目が同じ名前のデータがあり、’Name’列だけをキー列として結合する場合、この2個のデータを識別できませんが、’Name’と’Age’列の2個のキーを基に結合すれば、df3の0,4行目のデータを識別した上で結合できます。
df3 = df[['Embarked','Age','Name']].iloc[[6,9,10], :].reset_index(drop = True) df3.loc[3] = ['C', 35,'McCarthy, Mr. Timothy J'] df4 = df[['Age','Name','Fare','Sex']].iloc[[6,7,10], :].reset_index(drop = True)
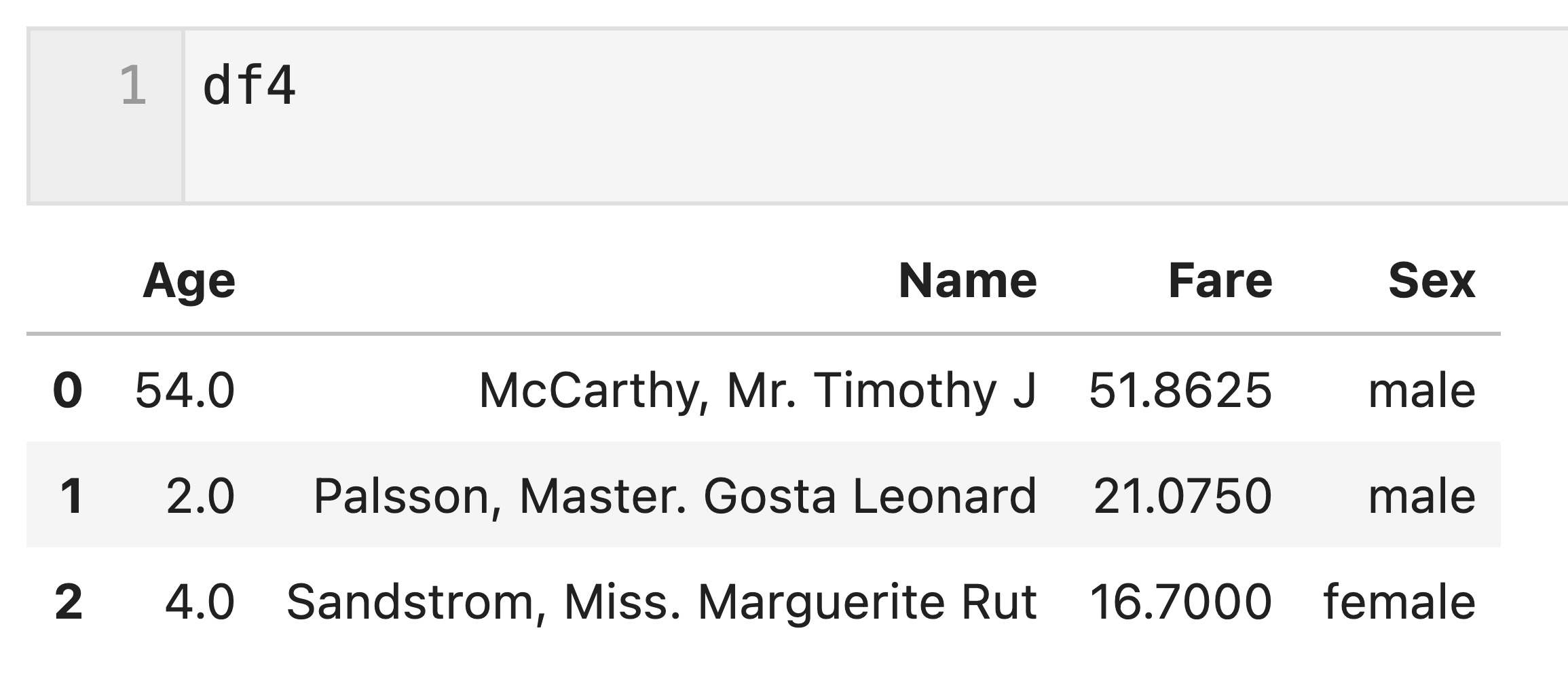
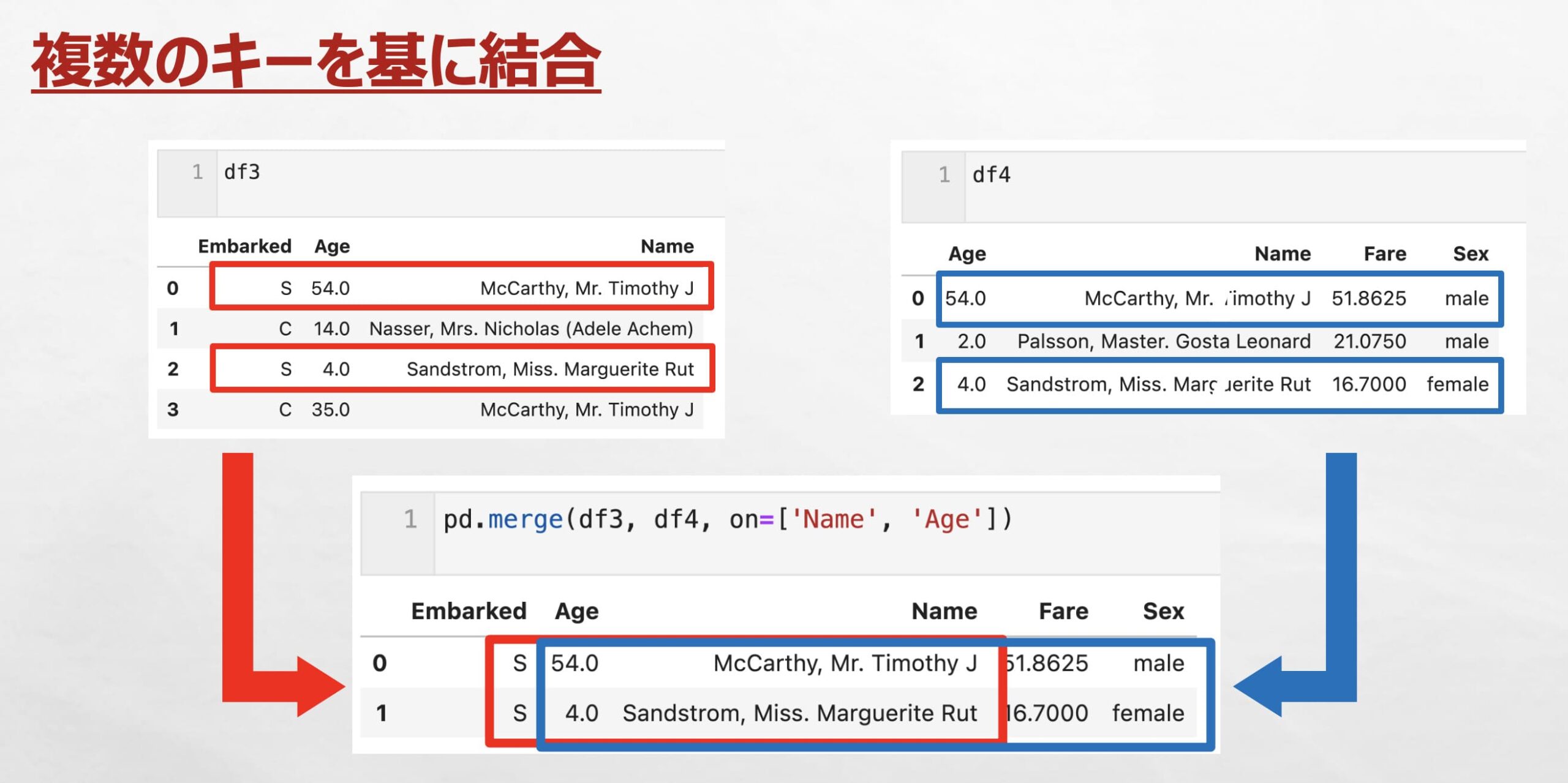
on = [‘Name’, ‘Age’]とすることで複数のキー(’Name’列、’Age’列の値)を基に結合できます。
df3には’Name’列に同じデータがありますが、’Name’列と’Age’列の2個のキーを基に結合することで、これら2個のデータを識別した上で結合できていることが確認できます。
pd.merge(df3, df4, on=['Name', 'Age'])
今回の記事はここまでです。
最後まで読んでいただきありがとうございました。
pythonを活用したデータサイエンスでは、データを結合するのは頻出なので、是非今回の記事で、Pandasのconcat関数の使い方をマスターしてください。
本記事が皆さんのお役に少しでも立てることを願っています。

