

今回の記事では下記の悩みを解消します。
「機械学習で構築したモデルの精度を評価する方法がわからない」
「機械学習の交差検証について知りたい」
「pythonのKFoldの使い方がわからない」
こんな悩みを解決していきます。
今回の記事では、機械学習(教師あり学習)で必須の『交差検証、特にKFold交差検証』について解説します。
機械学習(教師あり学習)では、データの学習と精度検証はセットで実施する必要がありますし、kaggleなどのコンペでも必要な知識なので、今回の記事で是非、理解してほしいです!
早速解説していきます。
交差検証とは
交差検証とは、構築したモデルの汎化性能(未知のデータに対する予測精度)を評価するための手法の1つです。
その中でKFold交差検証は、手持ちのデータをK個のグループに分割し、K回モデル構築・検証を実施し、個々の検証結果を統合して最終の検証結果とする手法です。
こう書くと難しいですが、「今手持ちのデータをどれくらい予測できるか」でモデルの汎化性能を評価しているんだ〜くらいの理解度でオッケーです🙆♀️
KFold交差検証の具体的な手順は下記。
① データの分割
手持ちのデータセットを同じサイズのK個のグループ(フォールド)に分割する。
② 学習用データを学習してモデルを訓練
分割したK個のうちの1つを検証用データとして残し、残りのK-1個を学習用データとしてモデルを訓練する。
③ ②で訓練したモデルの評価
訓練したモデルを使って、検証用データに対して予測を実施し、予測結果と実際のデータ(正解)を比較して、モデルの精度を評価する。
④ 全てのグループが一度は検証用データになるように②、③を繰り返す
図にすると下記のような感じ。(5分割交差検証を示してます)
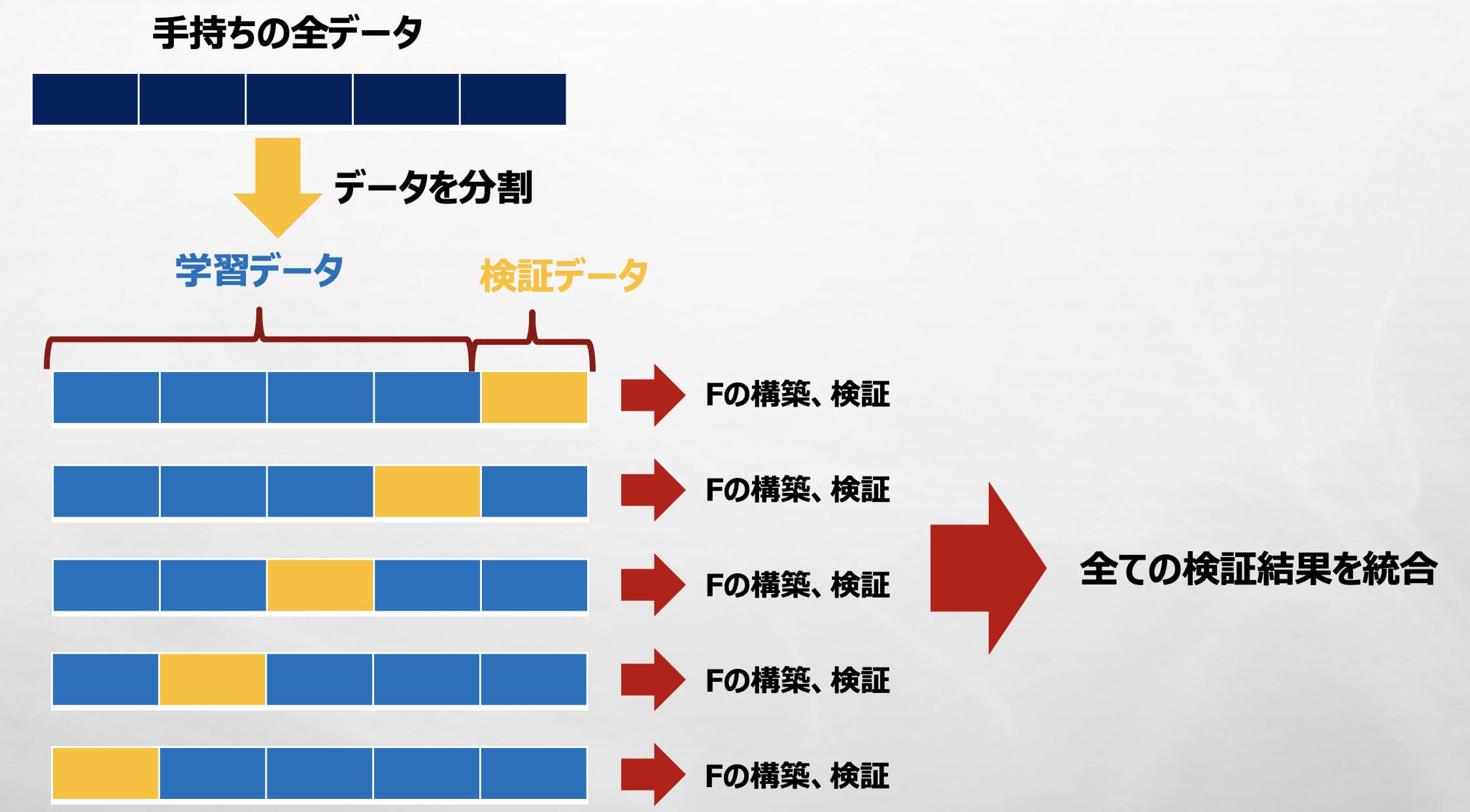
5つのグループに分割して、「モデルの訓練(Fの構築)・検証」を5回実施していますが、それぞれ学習データと検証データが変わるので、この5個の検証結果は変わります。
そして、この5個の検証結果を全て統合して最終の検証結果とします。
次に具体的に『pythonのKFold』の使い方を解説していきます。
pythonのKFoldの使い方
今回は、下記解説記事の「住宅価格予測問題」を使って、pythonのKFoldの使い方を解説します。

データの読み込みから前処理までは下記コードをコピペしてください。
(わからなければ上の解説記事を読んでみてください!)
#データの読み込み
from sklearn.datasets import fetch_openml
import pandas as pd
housing = fetch_openml(name="house_prices", as_frame=True)
X = housing.data #説明変数
y = housing.target #目的変数
df = pd.concat([X, y], axis = 1)
#欠損値の多い列の削除
df = df.drop(columns = ['Id'])
df = df.drop(columns = ['Alley','FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature'])
#文字列データのカラム名を選択し、欠損値を「最頻値」で補完
df_object = df.select_dtypes(include = ['object'])
df_object_NAN_columns = df_object.isnull().sum()[df_object.isnull().sum() > 0].index
for col in df_object_NAN_columns:
df.loc[df[col].isnull(), col] = df.loc[df[col].isnull(), col].fillna(df[col].mode()[0])
#数値データの欠損値を平均値で補完
df_numerical = df.select_dtypes(include = ['int', 'float64'])
df_numerical_NAN_columns = df_numerical.isnull().sum()[df_numerical.isnull().sum() > 0].index
for col in df_numerical_NAN_columns:
df.loc[df[col].isnull(), col] = df.loc[df[col].isnull(), col].fillna(df[col].mean())
#文字列のデータをダミー変数化
df = pd.get_dummies(df, drop_first = True)
#目的変数を対数変換(元のSalePriceを削除)
import numpy as np
df['log_SalePrice'] = np.log10(df['SalePrice'])
df = df.drop(columns = ['SalePrice'])
前処理後のdfは、1460行、233列のデータになります。
このdfを使ってKFoldの使い方を解説します。
まずは『KFoldのsplit( )関数』の使い方から書いていきます。
KFoldのsplit( )関数の使い方
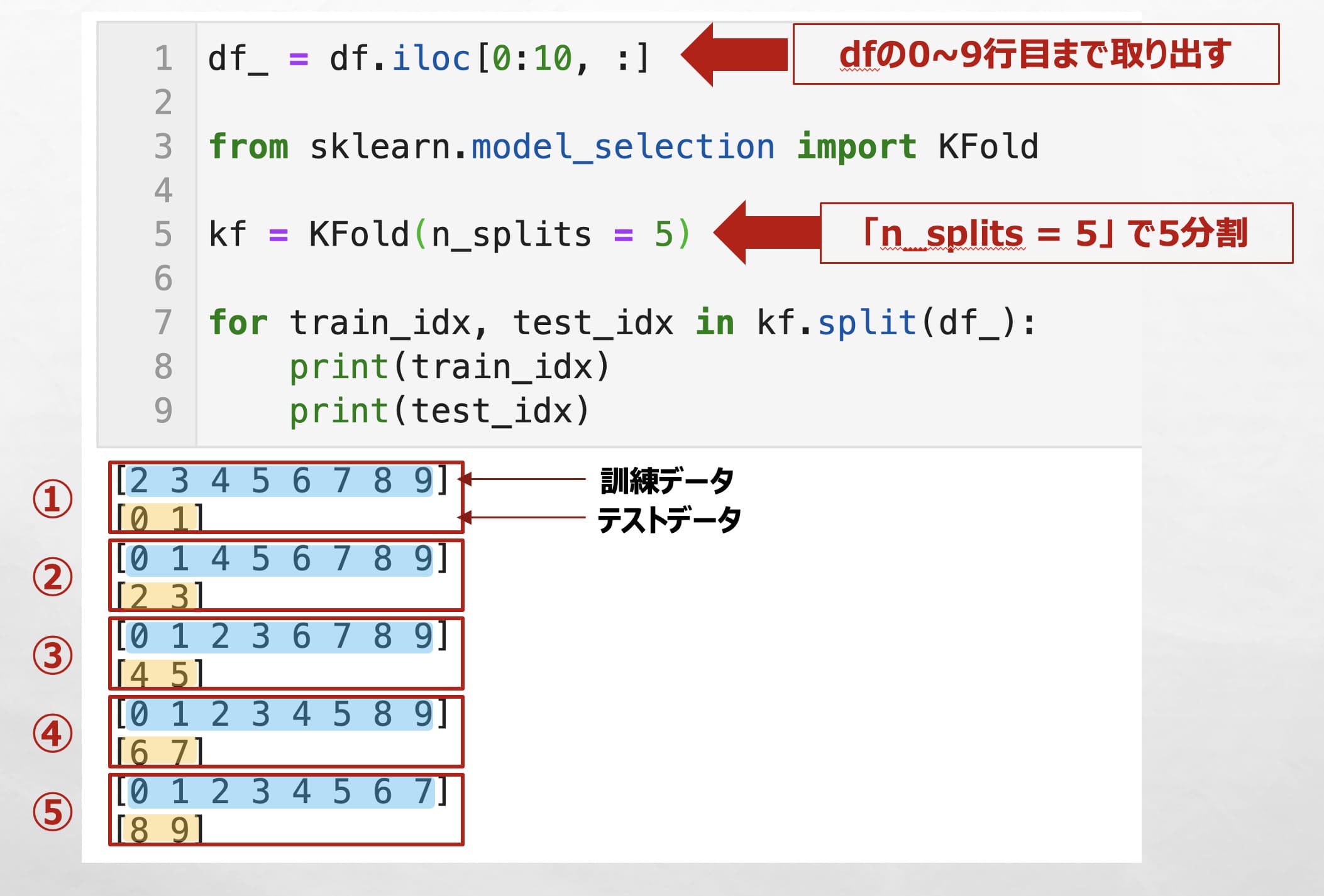
KFoldのsplit( )関数をdfに適用すると、データ分割後の学習用データと検証用データの行番号のリストを取得できます。
例えば、KFoldのsplit( )関数を使ってデータを分割し、for文で全てprintしてみます。
(下の例では、予めdfの10行目までを取り出して出力しています)
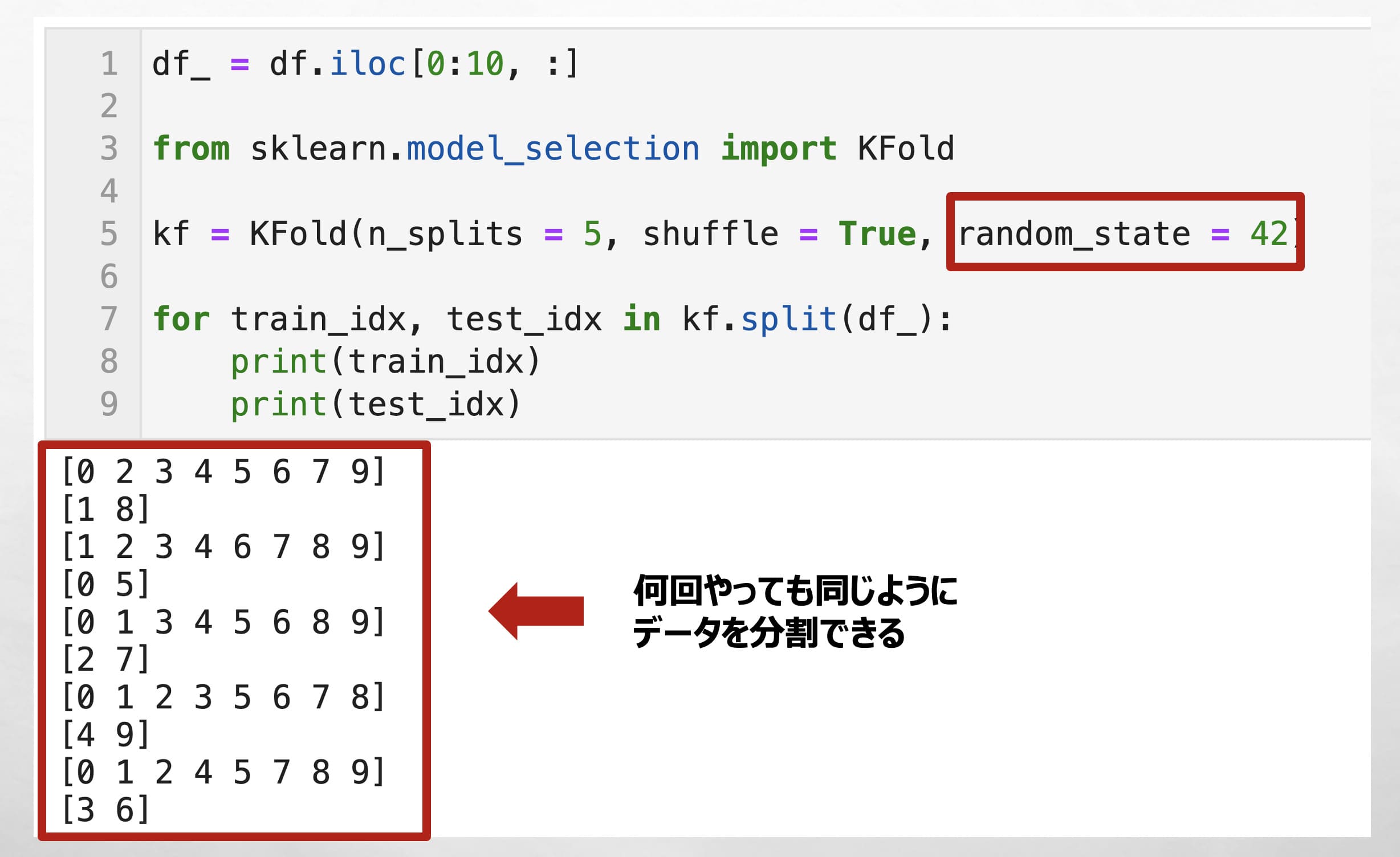
「n_splits = 5」とすることで、データを5分割することができ、また、全てのデータが1度はテストデータになっていることが確認できます。(テストデータの行番号が0~9すべてある)
df_ = df.iloc[0:10, :]
from sklearn.model_selection import KFold
kf = KFold(n_splits = 5)
for train_idx, test_idx in kf.split(df_):
print(train_idx)
print(test_idx)
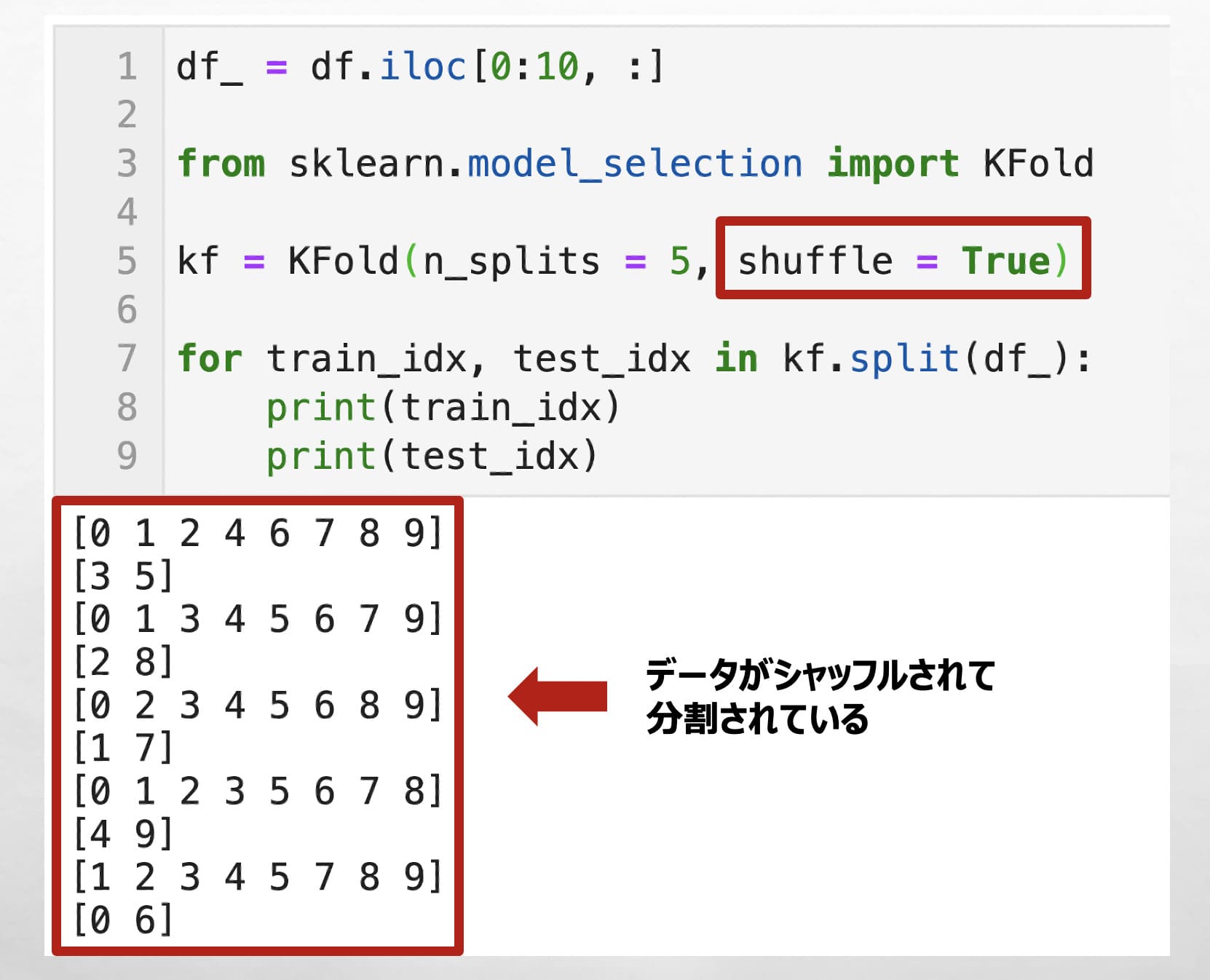
ここでKFoldのsplit( )関数でよく指定する引数を2個紹介します。
✅「shuffle = True」にすると、データがシャッフルされて分割できます。
df_ = df.iloc[0:10, :]
from sklearn.model_selection import KFold
kf = KFold(n_splits = 5, shuffle = True)
for train_idx, test_idx in kf.split(df_):
print(train_idx)
print(test_idx)
✅ 乱数指定「random_state = 42」をすることで、何回やっても同じようにデータを分割できます。
例えば、ハイパーパラメータを探索したりするときは、乱数を固定しておかないと、データの分割の仕方により最適なハイパーパラメータが変わってしまいます。
数字は幾つでもいいが42であることが多いです。
df_ = df.iloc[0:10, :]
from sklearn.model_selection import KFold
kf = KFold(n_splits = 5, shuffle = True, random_state = 42)
for train_idx, test_idx in kf.split(df_):
print(train_idx)
print(test_idx)
pythonのKFoldを使った交差検証の実践
さて具体的にここからは前処理後のdfを用いてモデル構築とpythonのKFoldを活用した交差検証を実施していきます。
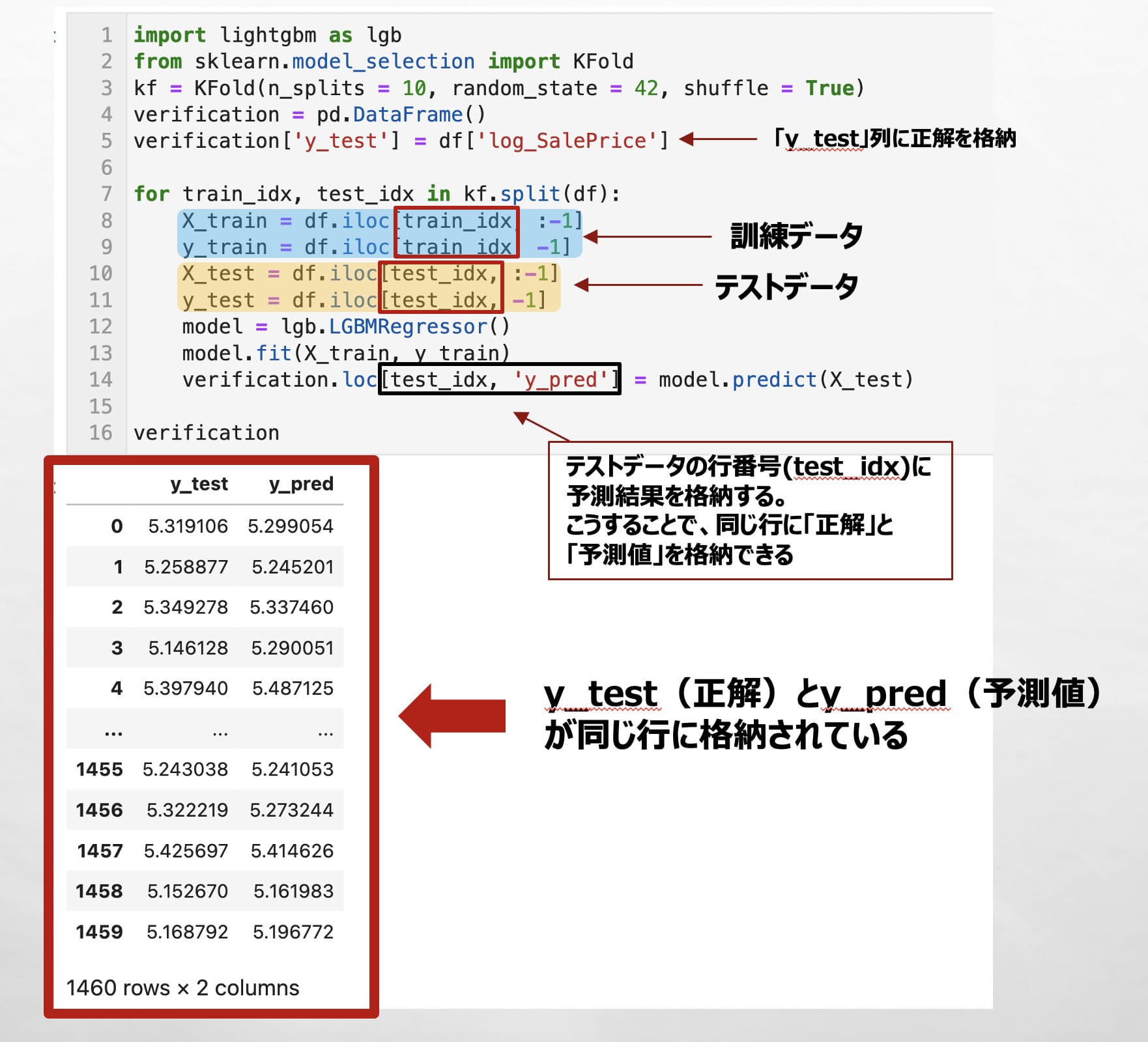
下記のコードでは、kf.split(df)で分割した訓練データの行番号(train_idx)、検証データの行番号(test_idx)を基に、訓練データ(X_train, y_train)、テストデータ(X_test, y_test)に分割しています。
そして訓練データを用いてLightGBMでモデル構築し、testデータを予測し、予測結果を行番号(test_idx)を指定してverificationに格納しています。
import lightgbm as lgb
from sklearn.model_selection import KFold
kf = KFold(n_splits = 10, random_state = 42, shuffle = True)
verification = pd.DataFrame()
verification['y_test'] = df['log_SalePrice']
for train_idx, test_idx in kf.split(df):
X_train = df.iloc[train_idx, :-1]
y_train = df.iloc[train_idx, -1]
X_test = df.iloc[test_idx, :-1]
y_test = df.iloc[test_idx, -1]
model = lgb.LGBMRegressor()
model.fit(X_train, y_train)
verification.loc[test_idx, 'y_pred'] = model.predict(X_test)
verification
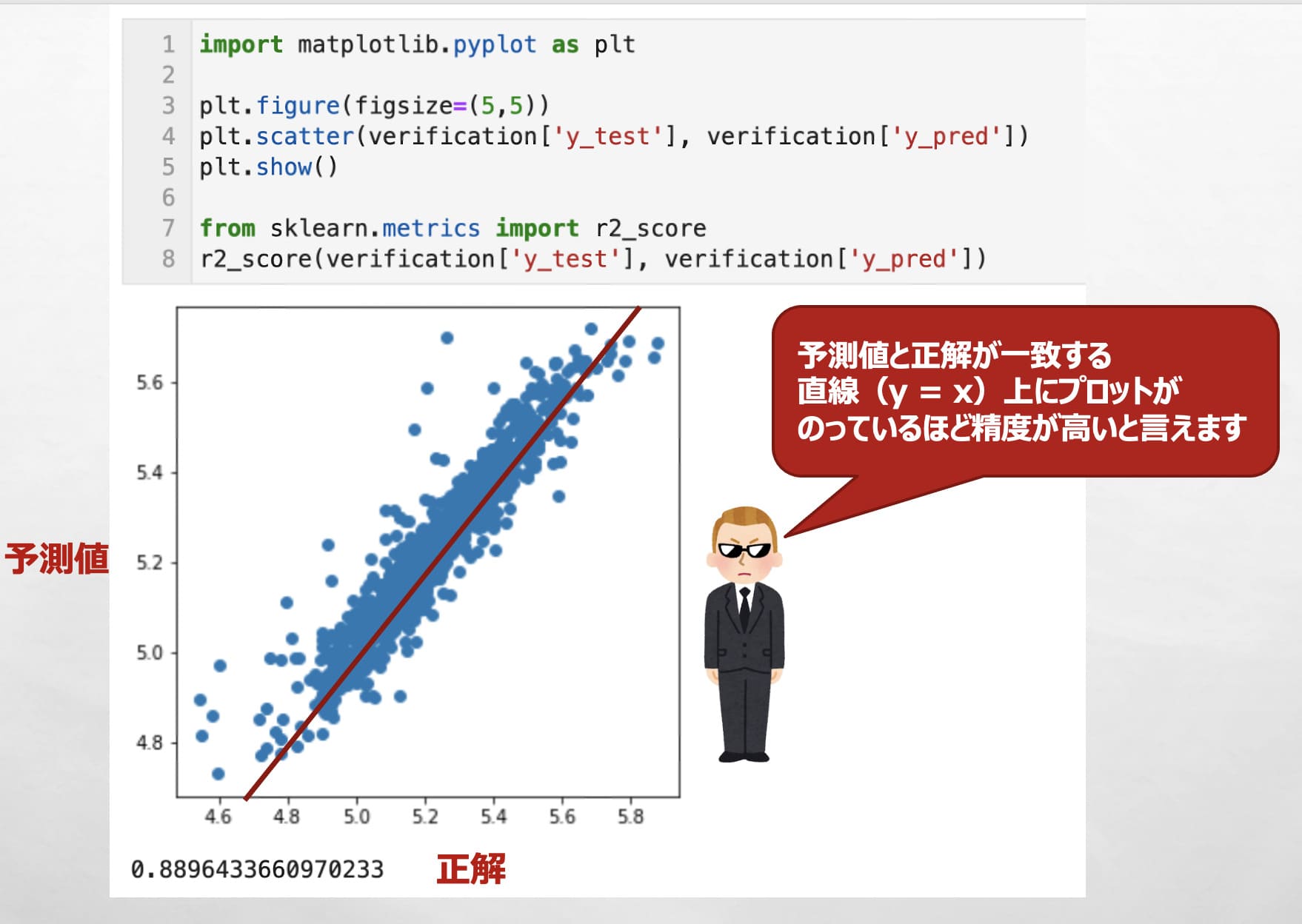
最後に先ほどのverificationを用いて、「正解」と「予測値」の散布図を作成し、直線「y = X」上にプロットがどれだけ乗っているかで精度を確認します。
定量的な数値で予測精度を確認したい場合は、r2_scoreもよく使われます。
散布図を見ると直線 y = X上にプロットが載っていることが確認でき、構築したモデルがまずまずの制度であることが確認できます。
import matplotlib.pyplot as plt plt.figure(figsize=(5,5)) plt.scatter(verification['y_test'], verification['y_pred']) # 散布図を描画 plt.show() from sklearn.metrics import r2_score r2_score(verification['y_test'], verification['y_pred'])
この記事は以上です。
pythonを活用したデータサイエンスではfor文を使った繰り返し処理は頻出なので、是非今回の記事でfor文の処理のイメージを掴んでいただければと思います。
✅ 機械学習・pythonの「勉強」について知りたい人は下記記事もお勧め
仕事で活用するための機械学習、pythonの「勉強」について解説しています。
機械学習の独学は勉強することが多く、特に挫折しがちです。。
機械学習を完全独学した私が、「社会で使える機械学習スキル」を最短で得るための勉強・勉強法について書いていますので是非読んで見てください。

皆さんのpythonに関する勉強がさらに進み、理解が深まることを願っています。

